flowchart TD A["Ingesta / Extracción"] --> B["EDA: Entender Datos"] B --> C["Limpieza: Faltantes, dominios, duplicados"] C --> D["Tratamiento: Transformaciones, escalado, codificación"] D --> E["Modelado / Inferencia"] E --> F["Monitoreo: Drift, calidad de datos"] %% Relaciones de retroalimentación B -.->|Retroalimentación| C C -.->|Si cambia distribución| B
4 Análisis Exploratorio de Datos (EDA): teoría, medidas y visualización
El Análisis Exploratorio de Datos (EDA) es la etapa donde se “conoce” el dataset antes de ajustar modelos o reportar métricas. Su objetivo operativo es contestar, con evidencia cuantitativa y visual:
- ¿Qué tan grande y qué tan completo es el conjunto de datos?
- ¿Qué tipos de variables hay y cuáles son sus valores permitidos?
- ¿Qué relaciones y estructuras aparecen entre variables?
- ¿Qué anomalías, inconsistencias o valores atípicos existen?
Estos puntos aparecen como objetivos explícitos del análisis de datos en la presentación (cantidad de datos, tipo, valores permitidos, relaciones y anomalías).
EDA no es “solo graficar”: es la base para decidir limpieza, tratamiento y transformaciones. En la práctica, EDA produce decisiones como:
- imputar, eliminar o marcar faltantes;
- corregir dominios inválidos (edades negativas, fechas imposibles);
- detectar y tratar outliers (winsorizar, transformar, segmentar, inspección manual);
- elegir escalas (log, estandarización) si hay rangos dinámicos grandes;
- identificar variables con baja variabilidad (casi constantes) que aportan poca información;
- detectar categorías raras (alta cardinalidad) que requieren agrupación o codificación distinta.
5 Tipos de variables y su impacto en el EDA
Clasificar correctamente el tipo de variable define qué operaciones estadísticas son válidas y qué visualizaciones son informativas. En EDA se distingue entre variables cualitativas y cuantitativas, con subtipos nominal/ordinal y discreta/continua. Esta clasificación guía la selección de medidas de tendencia central, dispersión, heterogeneidad y concentración, así como el tipo de gráfico (barras para categóricas, histogramas para continuas).
5.1 Cualitativas (categóricas)
- Nominales (sin orden intrínseco):
- Ejemplos: sexo, hospital, especialidad médica, tipo de cáncer, resultado de cita (asistió/no asistió), método de pago.
- Qué se analiza: frecuencias (f_k), proporciones (p_k), moda; heterogeneidad con entropía o Gini/impureza.
- Gráficas típicas: barras (sin asumir orden), pastel solo si hay pocas categorías y se justifica.
- Ordinales (con orden, pero sin “distancias” numéricas bien definidas):
- Ejemplos: prioridad (baja/media/alta), satisfacción (muy baja…muy alta), nivel de riesgo (1–5), severidad (leve/moderada/severa).
- Qué se analiza: frecuencias ordenadas, frecuencias acumuladas, mediana y cuantiles (cuando el orden es consistente).
- Gráficas típicas: barras ordenadas, acumuladas, y eventualmente gráficos de distribución por categorías si se cruza con una variable numérica.
Implicación clave: en nominales el orden no existe y no debe imponerse; en ordinales el orden sí importa, pero no conviene tratar los códigos como si fueran mediciones con diferencias métricas (p. ej., “alta=3” no implica que “alta” esté a la misma distancia de “media” que “media” de “baja”).
5.2 Cuantitativas (numéricas)
- Discretas (conteos enteros):
- Ejemplos: número de citas, cancelaciones por mes, número de derivaciones, cantidad de compras, número de visitas.
- Qué se analiza: media/varianza si el conteo es suficientemente grande, percentiles, asimetría; presencia de ceros y sobredispersión (varianza mayor que la media) como señal de modelos o transformaciones apropiadas.
- Gráficas típicas: barras/histogramas con bins enteros, “lollipop/stem” si hay pocos valores.
- Continuas (mediciones en escala real):
- Ejemplos: peso, estatura, duración (min), temperatura, distancia, presión arterial, ingreso mensual.
- Qué se analiza: media/mediana, desviación estándar, IQR, colas y asimetría; sensibilidad a outliers y necesidad de transformaciones (log, Box–Cox) si hay rangos dinámicos grandes.
- Gráficas típicas: histogramas, densidad (si aplica), boxplot/violin, ECDF.
Implicación clave: en discretas suele ser importante detectar acumulación en ciertos valores (heaping) y exceso de ceros; en continuas, la forma de la distribución (asimetría, colas pesadas, multimodalidad) guía transformaciones, segmentación y tratamiento de valores atípicos.
6 EDA univariado: frecuencias y distribución
En términos prácticos, el EDA univariado responde dos preguntas estructurales: qué valores aparecen y con qué frecuencia (dominio empírico), y cómo se distribuye la masa de probabilidad (PMF)1 (colas, asimetría y concentración). Esta etapa es más que un resumen descriptivo: al construir distribuciones empíricas se obtiene un mecanismo formal para auditar calidad de datos (dominios inválidos, faltantes, duplicados semánticos, codificaciones inconsistentes) y para anticipar decisiones de tratamiento (transformaciones, recodificaciones, segmentación y manejo de outliers).
1 PMF (Probability Mass Function): función de masa de probabilidad para variables discretas. Asigna a cada valor posible \(v\) una probabilidad \(P(X=v)\). En datos, la PMF empírica se estima con proporciones: \(\hat p(v)=\frac{\#\{i: x_i=v\}}{n}\).
6.1 Frecuencias, proporciones y acumuladas
Sea una variable categórica u ordinal/discreta con valores posibles \(v_1, \dots, v_K\) y una muestra \(x_1, \dots, x_n\). La frecuencia absoluta \(f_k\) cuenta cuántas observaciones caen exactamente en la categoría (o valor) \(v_k\), mientras que la frecuencia relativa \(p_k\) convierte ese conteo en proporción del total (por eso siempre \(0 \le p_k \le 1\)):
\[ f_k \;=\; \#\{\, i \in \{1,\dots,n\} : x_i = v_k \,\}, \qquad p_k \;=\; \frac{f_k}{n}. \]
Como \(n\) es el total de observaciones, se cumple que:
\[ \sum_{k=1}^{K} f_k = n \qquad\text{y}\qquad \sum_{k=1}^{K} p_k = 1. \]
La colección \((p_1,\dots,p_K)\) es la distribución empírica: resume “cómo se reparte” la muestra entre categorías y funciona como estimación no paramétrica de la PMF2 cuando la variable es discreta.
2 PMF (Probability Mass Function): función de masa de probabilidad para variables discretas. Asigna a cada valor posible \(v\) una probabilidad \(P(X=v)\). En datos, la PMF empírica se estima con proporciones: \(\hat p(v)=\frac{\#\{i: x_i=v\}}{n}\).
Cuando existe un orden natural en los valores (por ejemplo, una calificación 0–10, un conteo de días, o una variable ordinal con orden fijo), conviene acumular desde los valores más pequeños hacia los más grandes. Definimos:
- Frecuencia acumulada \(F_k\): cuántas observaciones son \(\le v_k\).
- Proporción acumulada \(P_k\): qué fracción del total es \(\le v_k\).
\[ F_k \;=\; \sum_{j \le k} f_j, \qquad P_k \;=\; \sum_{j \le k} p_j. \]
Como \(p_j=f_j/n\), también se puede ver directamente que:
\[ P_k = \frac{F_k}{n}. \]
Equivalentemente, \(P_k\) puede interpretarse como una CDF empírica discretizada3: mide la fracción de observaciones con valor “a lo más” \(v_k\) (o “no mayor que” \(v_k\)). Esta lectura hace que expresiones operativas sean inmediatas: por ejemplo, “29% del grupo obtuvo 7” corresponde a \(p_{\text{(valor=7)}} = 0.29\), y “58.1% obtuvo 7 o menos” corresponde a \(P_{\text{(valor=7)}} = 0.581\).
3 CDF (Cumulative Distribution Function): función de distribución acumulada. Da la probabilidad de observar un valor menor o igual a un umbral: \(F(v)=P(X\le v)\). En datos discretos ordenados, la CDF empírica coincide con la acumulada de proporciones: \(P_k=\sum_{j\le k} p_j\).
6.1.1 Ejemplo numérico
Supongamos una variable discreta calificación (tiene orden natural) y la siguiente muestra de tamaño \(n=10\):
\[ x = (6,\; 7,\; 8,\; 7,\; 5,\; 7,\; 6,\; 9,\; 5,\; 8). \]
Los valores distintos observados (ordenados) son:
\[ v_1=5,\; v_2=6,\; v_3=7,\; v_4=8,\; v_5=9. \]
Frecuencias absolutas \(f_k\)
Contamos cuántas veces aparece cada valor:
- Para \(v_1=5\): aparece 2 veces \(\Rightarrow f_1=2\)
- Para \(v_2=6\): aparece 2 veces \(\Rightarrow f_2=2\)
- Para \(v_3=7\): aparece 3 veces \(\Rightarrow f_3=3\)
- Para \(v_4=8\): aparece 2 veces \(\Rightarrow f_4=2\)
- Para \(v_5=9\): aparece 1 vez \(\Rightarrow f_5=1\)
Verificación:
\[ \sum_{k=1}^{5} f_k = 2+2+3+2+1 = 10 = n. \]
Proporciones \(p_k = f_k/n\)
Como \(n=10\):
\[ p_1=\frac{2}{10}=0.20,\quad p_2=\frac{2}{10}=0.20,\quad p_3=\frac{3}{10}=0.30,\quad p_4=\frac{2}{10}=0.20,\quad p_5=\frac{1}{10}=0.10. \]
Verificación:
\[ \sum_{k=1}^{5} p_k = 0.20+0.20+0.30+0.20+0.10 = 1.00. \]
Frecuencias acumuladas \(F_k\)
Acumulamos (porque hay orden natural):
\[ F_1=f_1=2 \]
\[ F_2=f_1+f_2=2+2=4 \]
\[ F_3=f_1+f_2+f_3=2+2+3=7 \]
\[ F_4=f_1+f_2+f_3+f_4=2+2+3+2=9 \]
\[ F_5=f_1+f_2+f_3+f_4+f_5=2+2+3+2+1=10 \]
Interpretación: \(F_3=7\) significa que 7 de 10 observaciones son 7 o menos.
Proporciones acumuladas \(P_k\)
Podemos acumular proporciones (o usar \(P_k = F_k/n\)):
\[ P_1=p_1=0.20 \]
\[ P_2=p_1+p_2=0.20+0.20=0.40 \]
\[ P_3=p_1+p_2+p_3=0.20+0.20+0.30=0.70 \]
\[ P_4=0.70+0.20=0.90 \]
\[ P_5=0.90+0.10=1.00 \]
Interpretación: \(P_4=0.90\) significa que 90% de las observaciones son 8 o menos.
Tabla de resumen
| valor \(v_k\) | frecuencia \(f_k\) | proporción \(p_k\) | acumulada \(F_k\) | acumulada \(P_k\) |
|---|---|---|---|---|
| 5 | 2 | 0.20 | 2 | 0.20 |
| 6 | 2 | 0.20 | 4 | 0.40 |
| 7 | 3 | 0.30 | 7 | 0.70 |
| 8 | 2 | 0.20 | 9 | 0.90 |
| 9 | 1 | 0.10 | 10 | 1.00 |
Con esto, afirmaciones operativas salen directo:
- “El 30% obtuvo 7” \(\Rightarrow p_{\text{(valor=7)}}=0.30\).
- “El 70% obtuvo 7 o menos” \(\Rightarrow P_{\text{(valor=7)}}=0.70\).
6.1.2 Conexión con limpieza y tratamiento
Una tabla de frecuencias no solo resume: audita. Si los datos incluyen faltantes, típicamente se observa que \(\sum_{k=1}^K f_k < n\) (faltantes implícitos) o aparece una “categoría” artificial tipo NA, N/A o -1 (faltantes explícitos codificados). Si existen valores fuera del dominio permitido (por ejemplo, calificaciones 11 cuando el rango es 0–10), éstos aparecen como niveles inesperados y se vuelven detectables sin ambigüedad.
Además, la acumulada \(P_k\) permite localizar problemas de cola y concentración: si un número pequeño de valores concentra una proporción grande de masa, puede tratarse de (i) un fenómeno real de distribución sesgada, (ii) errores sistemáticos de captura (redondeos, truncamientos), o (iii) mezcla de subpoblaciones. En cualquiera de los casos, el EDA no “corrige” automáticamente, pero produce la evidencia cuantitativa para decidir acciones como recodificar categorías, imputar faltantes, transformar escalas o segmentar el análisis.
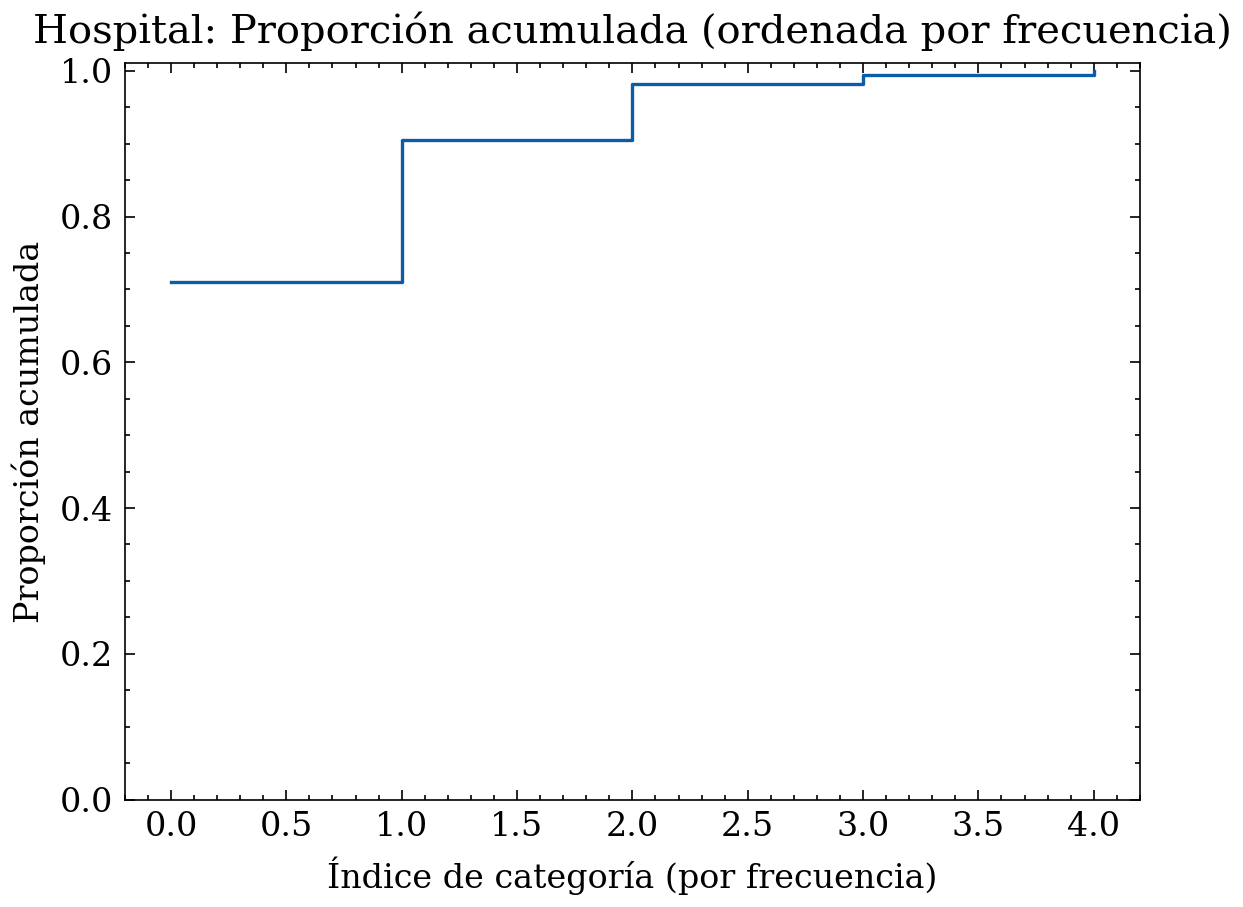
6.1.3 Ejemplo categórico: barras + acumulada
Supongamos que estamos trabajando con los datos de las citas de un hospital, y queremos analizar la variable categórica “resultado de cita” que tiene las categorías: “asistió”, “no asistió”, “canceló”, “NO SHOW” (duplicado semántico de “no asistió”) y “NA” (faltantes codificados). El siguiente código genera un dataset sintético con estas características, calcula frecuencias, proporciones y acumuladas, y muestra gráficos de barras y acumulada ordenada por frecuencia (tipo Pareto).
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
import scienceplots
plt.style.use('science')
mpl.rcParams["text.usetex"] = False
mpl.rcParams["figure.figsize"] = (5, 4) # o (10, 6)
mpl.rcParams["figure.dpi"] = 120
rng = np.random.default_rng(7)
# Variable categórica hospitalaria: resultado de cita
# Incluye duplicado semántico "NO SHOW" y faltantes codificados como "NA"
cats = np.array(["asistio", "no_asistio", "canceló", "NO SHOW", "NA"])
p = np.array([0.72, 0.18, 0.08, 0.02, 0.01]) # suma ~1.01; normalizamos por seguridad
p = p / p.sum()
x = rng.choice(cats, size=800, p=p)
# Conteos y proporciones
vals, counts = np.unique(x, return_counts=True)
order = np.argsort(-counts) # ordenar por frecuencia (desc) para lectura tipo Pareto
vals, counts = vals[order], counts[order]
n = counts.sum()
props = counts / n
cum_props = np.cumsum(props)
# Barras de frecuencia
plt.figure()
plt.bar(vals.astype(str), counts)
plt.title("Hospital: Frecuencias de resultado_cita")
plt.xlabel("resultado_cita")
plt.ylabel("Frecuencia")
plt.xticks(rotation=30, ha="right")
plt.tight_layout()
plt.show()
# Proporción acumulada (tipo Pareto, ordenada por frecuencia)
plt.figure()
plt.step(np.arange(len(vals)), cum_props, where="post")
plt.title("Hospital: Proporción acumulada (ordenada por frecuencia)")
plt.xlabel("Índice de categoría (por frecuencia)")
plt.ylabel("Proporción acumulada")
plt.ylim(0, 1.01)
plt.tight_layout()
plt.show()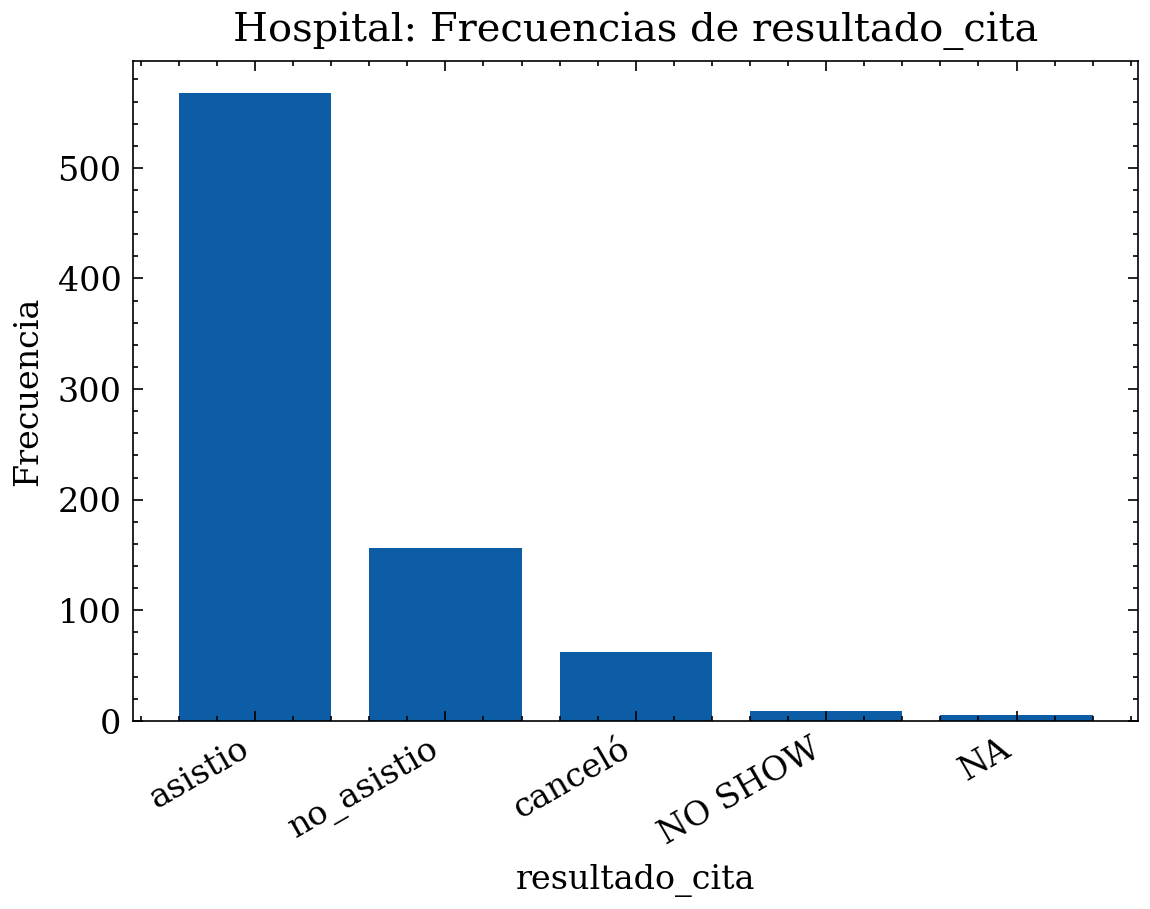
6.1.4 Ejemplo discreto: conteos + acumulada por valor
Para una variable discreta (conteos o calificaciones), conviene mirar la frecuencia por valor y su acumulada por orden natural del valor.
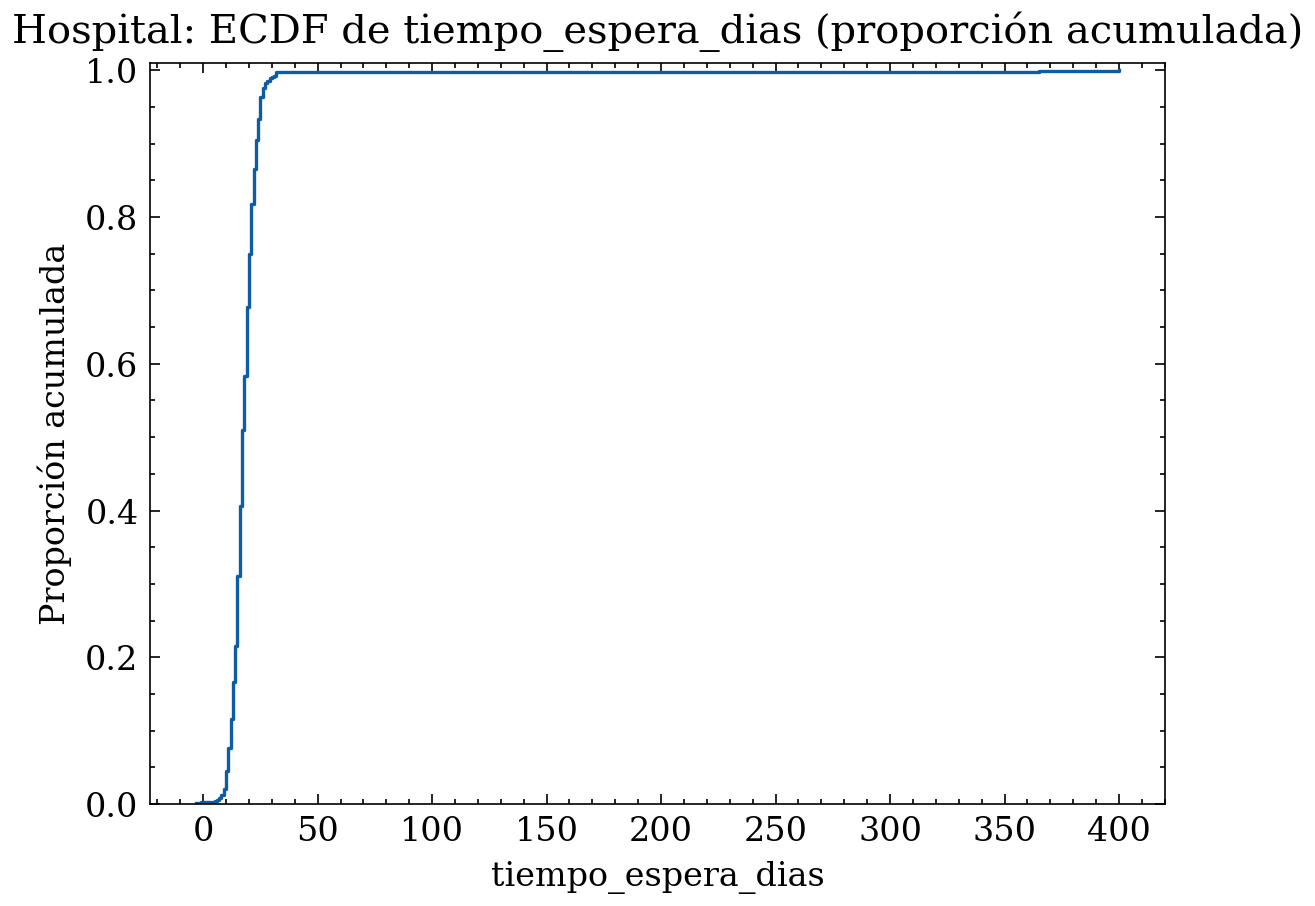
Para nuestro ejemplo del hospital, supongamos que analizamos la variable “tiempo_espera_dias” entre la solicitud de cita y la fecha de la cita. Esta variable es discreta (conteo de días) y tiene un rango típico (0–60), pero también puede contener valores inválidos (negativos, fechas mal parseadas). El siguiente código genera un dataset sintético con estas características, calcula frecuencias por valor, proporciones y acumuladas, y muestra gráficos de barras por valor y ECDF (proporción acumulada por valor).
rng = np.random.default_rng(11)
# Variable discreta hospitalaria: días de espera entre solicitud y cita
# La mayoría cae entre 0 y 60, pero metemos inválidos/extremos deliberados.
base = rng.poisson(lam=18, size=700) # masa típica de espera (0..~50)
base = np.clip(base, 0, 60) # política/realidad operativa
# "Inválidos" deliberados: negativos (fecha invertida), y extremos (fechas mal parseadas)
invalid = np.array([-3, -1, 365, 400]) # valores claramente fuera de rango
x = np.concatenate([base, invalid])
# Conteos y acumulada por orden natural del valor
vals, counts = np.unique(x, return_counts=True)
order = np.argsort(vals)
vals, counts = vals[order], counts[order]
n = counts.sum()
props = counts / n
cum_props = np.cumsum(props)
plt.figure()
plt.bar(vals, counts)
plt.title("Hospital: Frecuencias de tiempo_espera_dias")
plt.xlabel("tiempo_espera_dias")
plt.ylabel("Frecuencia")
plt.tight_layout()
plt.show()
plt.figure()
plt.step(vals, cum_props, where="post")
plt.title("Hospital: ECDF de tiempo_espera_dias (proporción acumulada)")
plt.xlabel("tiempo_espera_dias")
plt.ylabel("Proporción acumulada")
plt.ylim(0, 1.01)
plt.tight_layout()
plt.show()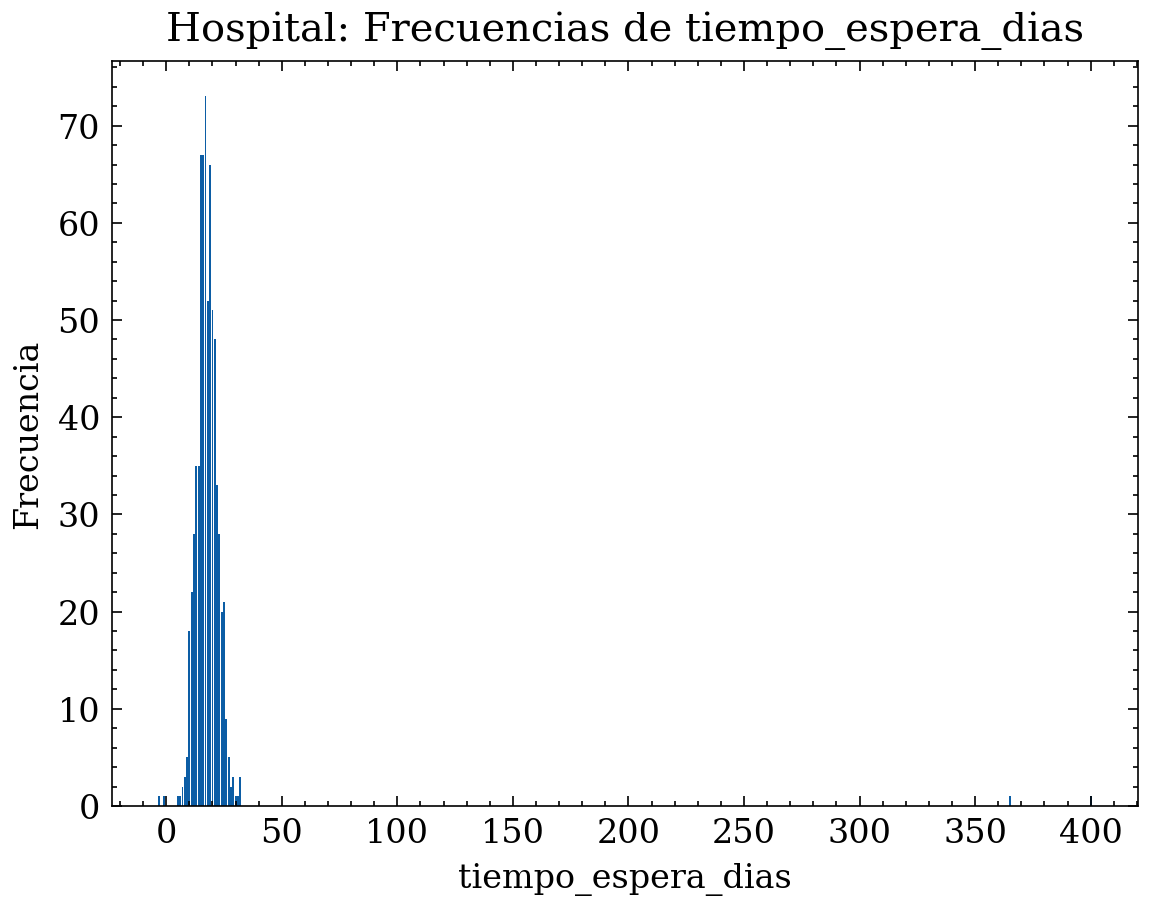
7 Medidas de localización (tendencia central)
En análisis univariado, las medidas de localización funcionan como un “ancla” para describir dónde se concentra la masa de la distribución. Desde el punto de vista del tratamiento de datos, su valor no es solo descriptivo: determinan estrategias de imputación, afectan la estabilidad numérica de transformaciones y permiten diagnosticar sensibilidad a colas pesadas y valores atípicos. En particular, cuando existe asimetría u outliers, distintas medidas de localización pueden separar “lo típico” de “lo extremo”, lo cual orienta decisiones como usar transformaciones (log), reglas robustas (IQR), o imputación basada en cuantiles.
7.1 Media
Para \(n\) observaciones \(x_1,\dots,x_n\), la media muestral (promedio) es:
\[ \bar{x} \;=\; \frac{1}{n}\sum_{i=1}^n x_i. \]
La media tiene una propiedad algebraica fundamental llamada linealidad (o afinidad)4:
4 Linealidad/Afinidad: propiedad por la cual si transformas los datos con \(aX+b\) (escala \(a\) y traslación \(b\)), la media se transforma igual: \(\overline{aX+b}=a\bar{X}+b\).
\[ \overline{aX+b} \;=\; a\,\bar{X} + b, \]
lo que explica por qué es natural en modelos aditivos y por qué se comporta bien bajo cambios de escala y traslación. Sin embargo, su principal limitación en EDA es su no robustez5: un solo valor extremo puede afectar \(\bar{x}\) de forma desproporcionada. Esto se entiende porque la media “promedia” magnitudes y, por tanto, responde directamente al tamaño del outlier6.
5 Robustez: capacidad de una estadística de no cambiar mucho ante valores atípicos o pequeñas “contaminaciones” en los datos. La mediana es robusta en comparación con la media.
6 Outlier (valor atípico): observación extremadamente grande o pequeña respecto a la mayoría. Puede ser error o un caso real raro.
Una forma operativa de detectar este problema es comparar \(\bar{x}\) con la mediana: si difieren mucho, suele haber asimetría y/o colas pesadas, y conviene considerar medidas robustas o transformaciones.
Ejemplo numérico
Supongamos \(n=5\) observaciones: \[ x = (2,\;3,\;3,\;4,\;8). \] 1) Suma: \[ \sum_{i=1}^5 x_i = 2+3+3+4+8 = 20. \] 2) Media: \[ \bar{x} = \frac{1}{5}\cdot 20 = 4. \]
Ahora veamos el efecto de un valor extremo: cambiemos el último valor de \(8\) a \(80\): \[ x'=(2,\;3,\;3,\;4,\;80). \] 1) Suma: \[ \sum_{i=1}^5 x'_i = 2+3+3+4+80 = 92. \] 2) Media: \[ \bar{x}' = \frac{92}{5} = 18.4. \]
Interpretación: solo cambiamos un dato (de 8 a 80) y la media subió de 4 a 18.4, ilustrando su sensibilidad a outliers.
7.2 Mediana
La mediana es el cuantil \(0.5\) (el “valor central”)7. Si \(x_{(1)}\le \dots \le x_{(n)}\) denota el reordenamiento de los datos, entonces:
7 Cuantil: valor que deja una fracción fija de observaciones por debajo. El cuantil \(0.5\) (50%) es la mediana: aproximadamente la mitad de los datos queda \(\le \tilde{x}\) y la otra mitad \(\ge \tilde{x}\).
\[ \tilde{x} \;=\; \begin{cases} x_{((n+1)/2)} & \text{si $n$ es impar},\\[6pt] \frac{1}{2}\left(x_{(n/2)} + x_{(n/2+1)}\right) & \text{si $n$ es par}. \end{cases} \]
A diferencia de la media, la mediana depende del orden y no de la magnitud exacta de valores extremos. Por eso es una medida robusta8: su valor no cambia mientras los outliers9 no alteren de manera sustancial el orden central de la muestra. En EDA, esta propiedad es especialmente útil para:
8 Robustez: capacidad de una estadística de no cambiar mucho ante valores atípicos o pequeñas “contaminaciones” en los datos. La mediana es robusta en comparación con la media.
9 Outlier (valor atípico): observación extremadamente grande o pequeña respecto a la mayoría. Puede ser error o un caso real raro.
- describir el “valor típico” cuando la distribución es sesgada (por ejemplo, tiempos, ingresos, montos);
- definir imputación robusta para variables continuas con outliers;
- comparar con \(\bar{x}\) para diagnosticar asimetría (si \(\bar{x}>\tilde{x}\), suele haber cola derecha).
Ejemplo numérico
Caso 1: \(n\) impar
Datos: \(x=(2,\,3,\,3,\,4,\,80)\) (ya están ordenados).
Como \(n=5\) es impar, la mediana es el elemento central:
\[ \tilde{x}=x_{((5+1)/2)}=x_{(3)}=3. \]
Caso 2: \(n\) par
Datos: \(x=(1,\,2,\,4,\,7)\) (ordenados).
Como \(n=4\) es par, promediamos los dos del centro:
\[ \tilde{x}=\frac{1}{2}\left(x_{(4/2)}+x_{(4/2+1)}\right) =\frac{1}{2}(x_{(2)}+x_{(3)}) =\frac{1}{2}(2+4)=3. \]
Interpretación: en el Caso 1, aunque hay un valor extremo (80), la mediana sigue siendo 3, mostrando su robustez.
7.3 Moda
La moda es el valor (o categoría) con frecuencia máxima10. Para variables discretas o categóricas, puede formalizarse como:
10 Frecuencia (absoluta): número de veces que aparece un valor/categoría en la muestra. Por ejemplo, si “asistió” aparece 3 veces, su frecuencia es 3.
\[ \operatorname{mode}(x)\;=\;\arg\max_{v_k}\; f_k, \]
donde \(f_k\) es la frecuencia absoluta del nivel \(v_k\). Es especialmente informativa en variables nominales11 (donde media/mediana no aplican) y también aparece en discretas cuando existe un valor dominante (por ejemplo, muchos ceros).
11 Nominal (variable categórica nominal): categorías sin orden intrínseco (p. ej., “asistió/no asistió/canceló”, “hospital”, “método de pago”). En nominales no tiene sentido hablar de “promedio” o “mediana”.
12 Multimodalidad: situación donde hay más de una moda (varios valores/categorías empatan como los más frecuentes). En este caso se reporta el conjunto de modas o se cambia el tipo de resumen.
En limpieza, la moda suele revelar codificaciones problemáticas: si “NA”, “No aplica” o “-” resultan ser la categoría más frecuente, es probable que exista un problema de captura o estandarización de faltantes. También puede ser ambigua si existen varias categorías con la misma frecuencia máxima (multimodalidad)12, lo cual requiere reportarla como conjunto de modos o cambiar de resumen.
Ejemplo numérico
Caso 1: moda única
Sea la muestra (categórica): \[ x=(\text{asistió},\ \text{no asistió},\ \text{asistió},\ \text{canceló},\ \text{asistió}). \] Contamos frecuencias:
- \(f(\text{asistió})=3\)
- \(f(\text{no asistió})=1\)
- \(f(\text{canceló})=1\)
Como 3 es la frecuencia mayor, la moda es: \[ \operatorname{mode}(x)=\text{asistió}. \] Caso 2: dos modas (multimodal)
Sea: \[
x=(1,\ 1,\ 2,\ 2,\ 3).
\] Frecuencias: \(f(1)=2\), \(f(2)=2\), \(f(3)=1\).
Aquí hay empate en la frecuencia máxima, así que hay dos modas: \[
\operatorname{mode}(x)=\{1,\,2\}.
\]
7.4 Ejemplo (e-commerce): gasto por compra con cola derecha (media vs mediana)
Contexto: variable continua monto_compra (MXN) en una tienda en línea. En la mayoría de pedidos el gasto es moderado, pero existen compras muy grandes (empresas, mayoreo) o registros anómalos (error de decimal). Esto genera cola derecha y outliers.
Diagnóstico EDA (conciso): - Si \(\bar{x} \gg \tilde{x}\), la distribución es asimétrica y está dominada por pocos montos muy altos. - En ese caso, la media deja de representar lo “típico”; la mediana es un mejor centro robusto. - La ECDF revela percentiles operativos (p. ej., P90, P95, P99) y permite fijar umbrales de auditoría (valores extremos para revisión). - Acciones típicas: usar \(\log(1+x)\) para modelar, winsorizar extremos, o segmentar (minorista vs mayoreo).
# Monto de compra: mayoría "normal" (lognormal moderada) + pocos pedidos grandes (outliers)
base = rng.lognormal(mean=4.5, sigma=0.45, size=800) # ~ montos típicos
outliers = rng.lognormal(mean=7.2, sigma=0.25, size=10) # pedidos enormes
monto_compra = np.concatenate([base, outliers])
mean = monto_compra.mean()
median = np.median(monto_compra)
# --- Moda (aprox) para variable continua: usando el bin con mayor frecuencia ---
bins = 50
counts, bin_edges = np.histogram(monto_compra, bins=bins)
max_bin_idx = np.argmax(counts)
mode_approx = 0.5 * (bin_edges[max_bin_idx] + bin_edges[max_bin_idx + 1]) # centro del bin modal
plt.figure()
plt.hist(monto_compra, bins=bins, alpha=0.45, edgecolor="white") # transparencia + mejor lectura
plt.title("E-commerce: histograma de monto_compra (cola derecha)")
plt.xlabel("monto_compra (MXN)")
plt.ylabel("Frecuencia")
# Líneas (cada medida con color distinto)
plt.axvline(mean, color="tab:blue", linestyle="--", linewidth=2, label=f"Media = {mean:.0f}")
plt.axvline(median, color="tab:orange", linestyle="-", linewidth=2, label=f"Mediana = {median:.0f}")
plt.axvline(mode_approx, color="tab:green", linestyle=":", linewidth=2,
label=f"Moda (aprox) = {mode_approx:.0f}")
plt.legend()
plt.tight_layout()
plt.show()
# ECDF para percentiles y cola
x_sorted = np.sort(monto_compra)
y = np.arange(1, x_sorted.size + 1) / x_sorted.size
plt.figure()
plt.step(x_sorted, y, where="post")
plt.title("E-commerce: ECDF de monto_compra (percentiles y cola)")
plt.xlabel("monto_compra (MXN)")
plt.ylabel("Proporción acumulada")
plt.ylim(0, 1.01)
plt.tight_layout()
plt.show()
# Percentiles operativos (útiles para auditoría y umbrales)
p90, p95, p99 = np.quantile(monto_compra, [0.90, 0.95, 0.99])
print(f"P90={p90:.0f} MXN, P95={p95:.0f} MXN, P99={p99:.0f} MXN")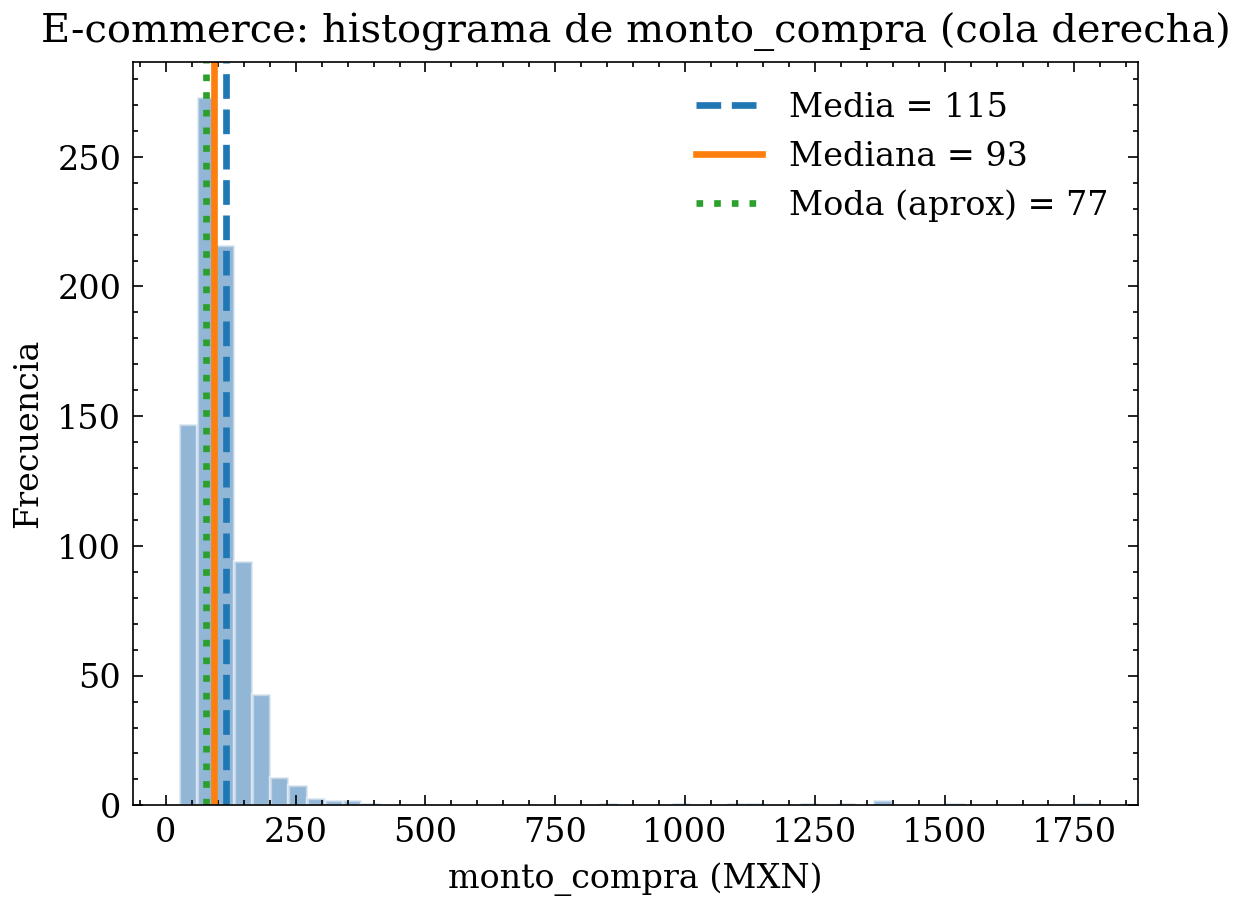
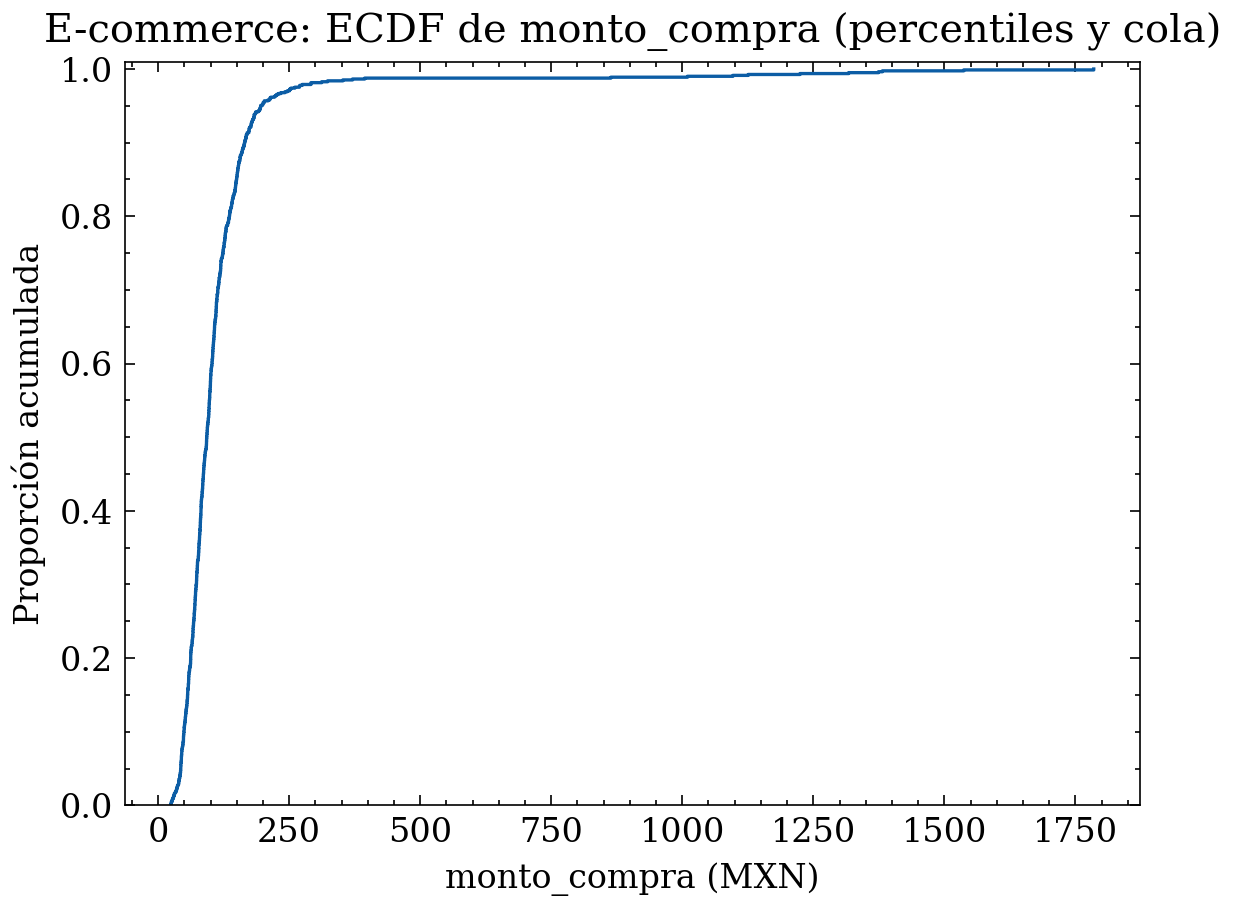
P90=165 MXN, P95=196 MXN, P99=997 MXN8 Medidas de forma: asimetría y curtosis
Además de saber dónde está la distribución (media/mediana), en EDA interesa caracterizar cómo es su geometría global. Las medidas de forma permiten describir si la distribución está cargada hacia un lado (asimetría) y qué tan “extremas” son sus colas (curtosis). Esto es especialmente útil para decidir transformaciones (log, Box–Cox), detectar colas pesadas y justificar estrategias robustas frente a valores atípicos.
Para formalizar estas medidas se utilizan momentos centrales muestrales. Dada una muestra \(x_1,\dots,x_n\) con media \(\bar{x}\), el momento central de orden \(r\) es:
\[ m_r \;=\; \frac{1}{n}\sum_{i=1}^n (x_i-\bar{x})^r. \]
En particular, \(m_2\) captura dispersión; \(m_3\) y \(m_4\) capturan forma (asimetría/colas) más allá de la varianza.
8.1 Asimetría (skewness)
La asimetría cuantifica si la distribución tiene una cola más larga o más pesada hacia la derecha o hacia la izquierda. Se define como el tercer momento central normalizado:
\[ \mathrm{skew} \;=\; \frac{m_3}{m_2^{3/2}}. \]
Interpretación práctica: - \(\mathrm{skew} > 0\): cola derecha más larga (ingresos, montos, tiempos). - \(\mathrm{skew} < 0\): cola izquierda más larga (variables “topadas” con pocos valores muy bajos). - \(\mathrm{skew} \approx 0\): distribución aproximadamente simétrica.
¿Para qué sirve en EDA? Un skew grande sugiere que la media puede ser poco representativa y que convienen transformaciones monotónicas (como \(\log(1+x)\)) o resúmenes robustos (mediana/IQR).
Ejemplo numérico
Tomemos una muestra muy pequeña con cola derecha:
\[ x=(1,\;2,\;2,\;3,\;10), \quad n=5. \]
- Media:
\[ \bar{x}=\frac{1+2+2+3+10}{5}=\frac{18}{5}=3.6. \]
- Desviaciones respecto a la media \((x_i-\bar{x})\):
- \(1-3.6=-2.6\)
- \(2-3.6=-1.6\)
- \(2-3.6=-1.6\)
- \(3-3.6=-0.6\)
- \(10-3.6=6.4\)
- Segundo momento central (dispersión):
\[ m_2=\frac{1}{5}\left[(-2.6)^2+(-1.6)^2+(-1.6)^2+(-0.6)^2+(6.4)^2\right] \]
Calculando:
- \((-2.6)^2=6.76\)
- \((-1.6)^2=2.56\) (dos veces)
- \((-0.6)^2=0.36\)
- \((6.4)^2=40.96\)
Suma \(=6.76+2.56+2.56+0.36+40.96=53.20\), entonces:
\[ m_2=\frac{53.20}{5}=10.64. \]
- Tercer momento central (asimetría sin normalizar):
\[ m_3=\frac{1}{5}\left[(-2.6)^3+(-1.6)^3+(-1.6)^3+(-0.6)^3+(6.4)^3\right] \]
Calculando:
- \((-2.6)^3=-17.576\)
- \((-1.6)^3=-4.096\) (dos veces)
- \((-0.6)^3=-0.216\)
- \((6.4)^3=262.144\)
Suma \(=-17.576-4.096-4.096-0.216+262.144=236.160\), entonces:
\[ m_3=\frac{236.160}{5}=47.232. \]
- Skewness:
\[ \mathrm{skew}=\frac{m_3}{m_2^{3/2}} =\frac{47.232}{(10.64)^{3/2}}. \]
Como \((10.64)^{3/2}=10.64\sqrt{10.64}\approx 10.64(3.262)\approx 34.70\),
\[ \mathrm{skew}\approx \frac{47.232}{34.70}\approx 1.36. \]
Conclusión: \(\mathrm{skew}\approx 1.36>0\), consistente con una cola derecha (el valor 10 “jala” la distribución hacia la derecha).
8.1.1 Gráfica: distribución simétrica vs sesgada (skewness)
En este ejemplo exploramos los tiempos de respuesta de un sistema (API / microservicio). Este tipo de variable suele ser sesgada a la derecha: la mayoría de peticiones son rápidas, pero existen “slow queries”, picos de carga o problemas de red que generan una cola larga.
rng = np.random.default_rng(123)
n = 5000
# Caso 1 (simétrico): "ruido" alrededor de un tiempo típico (modelo simplificado)
# Piensa en un sistema muy estable: latencia ~ Normal alrededor de 120 ms
lat_sym = rng.normal(loc=120.0, scale=15.0, size=n)
lat_sym = np.clip(lat_sym, 1e-3, None) # latencias no negativas
# Caso 2 (sesgado): latencias con cola derecha (lognormal)
# La mayoría cerca de 120 ms, pero con eventos raros muy lentos
lat_skew = rng.lognormal(mean=np.log(120.0), sigma=0.35, size=n)
def skew_kurt(x):
x = np.asarray(x)
mu = x.mean()
m2 = np.mean((x - mu)**2)
m3 = np.mean((x - mu)**3)
m4 = np.mean((x - mu)**4)
skew = m3 / (m2**1.5)
kurt = m4 / (m2**2)
return skew, kurt
sk_sym, ku_sym = skew_kurt(lat_sym)
sk_skew, ku_skew = skew_kurt(lat_skew)
plt.figure()
plt.hist(lat_sym, bins=70, density=True, alpha=0.35, label=f"Estable (skew={sk_sym:.2f})")
plt.hist(lat_skew, bins=70, density=True, alpha=0.35, label=f"Con cola (skew={sk_skew:.2f})")
plt.title("Asimetría en latencias: simétrica vs sesgada (densidad)")
plt.xlabel("latencia (ms)")
plt.ylabel("Densidad")
plt.legend()
plt.tight_layout()
plt.show()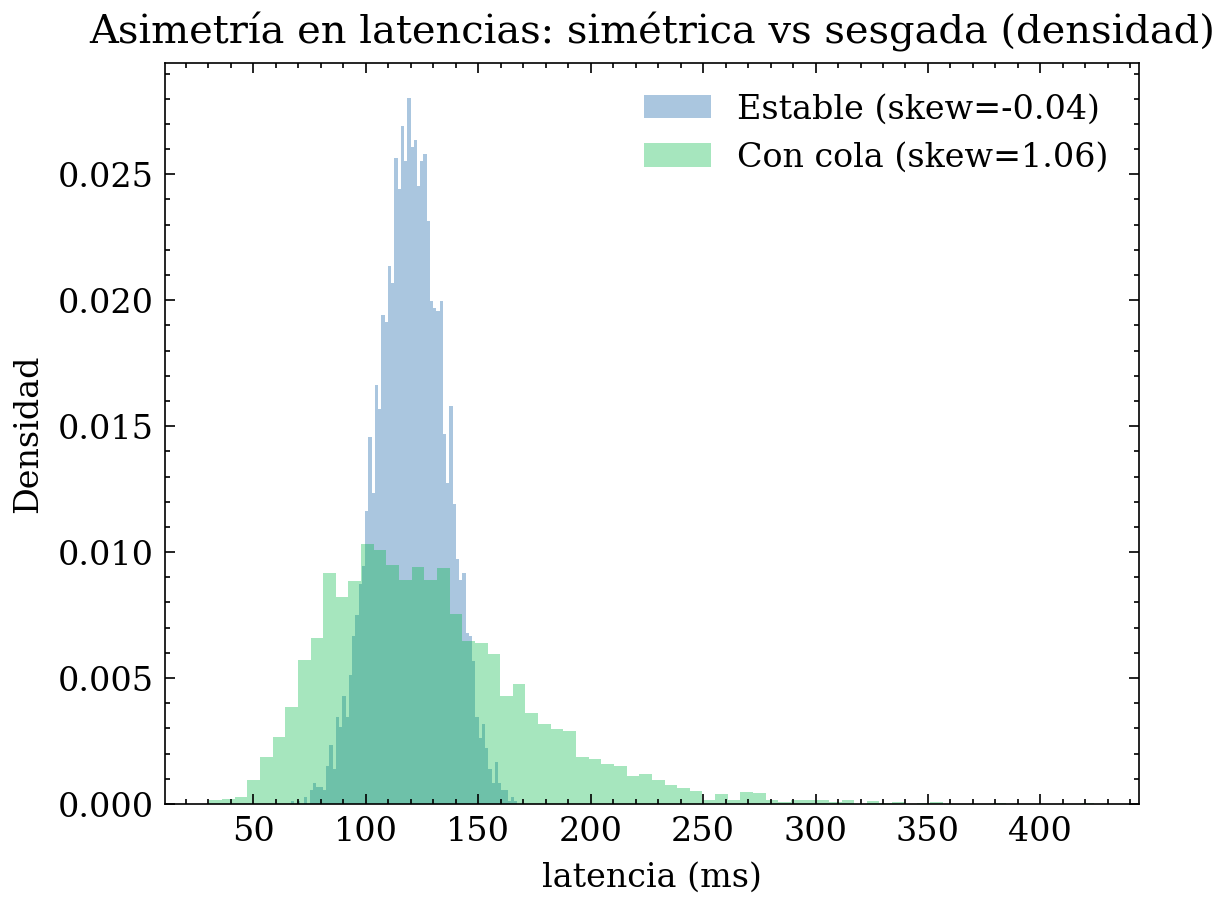
8.2 Curtosis (kurtosis)
La curtosis mide el comportamiento de las colas en relación con la dispersión central. En EDA se interpreta como un indicador de colas pesadas y, por tanto, de mayor probabilidad de observar valores extremos. Se define como el cuarto momento central normalizado:
\[ \mathrm{kurt} \;=\; \frac{m_4}{m_2^{2}}. \]
Una Normal ideal cumple \(\mathrm{kurt}=3\), por lo que también se usa el exceso de curtosis:
\[ \mathrm{kurt\_excess} \;=\; \mathrm{kurt}-3. \]
Interpretación práctica: - \(\mathrm{kurt}\) alto (o exceso positivo): colas pesadas → más extremos/outliers esperables. - \(\mathrm{kurt}\) cercano a 3: colas similares a la Normal. - \(\mathrm{kurt}\) bajo (exceso negativo): colas ligeras → extremos menos frecuentes.
¿Para qué sirve en EDA? Curtosis alta motiva revisar calidad de datos (errores vs casos raros reales), usar métodos robustos, o segmentar/transformar antes de ajustar modelos que sean sensibles a outliers.
Ejemplo numérico
Tomemos una muestra pequeña con valores extremos (colas pesadas):
\[ x=(0,\;0,\;0,\;0,\;10), \quad n=5. \]
- Media:
\[ \bar{x}=\frac{0+0+0+0+10}{5}=\frac{10}{5}=2. \]
- Desviaciones \((x_i-\bar{x})\):
- para los cuatro ceros: \(0-2=-2\)
- para el 10: \(10-2=8\)
- Segundo momento central:
\[ m_2=\frac{1}{5}\left[(-2)^2+(-2)^2+(-2)^2+(-2)^2+(8)^2\right] \]
\[ m_2=\frac{1}{5}\left[4+4+4+4+64\right] =\frac{80}{5}=16. \]
- Cuarto momento central:
\[ m_4=\frac{1}{5}\left[(-2)^4+(-2)^4+(-2)^4+(-2)^4+(8)^4\right] \]
\[ m_4=\frac{1}{5}\left[16+16+16+16+4096\right] =\frac{4160}{5}=832. \]
- Curtosis:
\[ \mathrm{kurt}=\frac{m_4}{m_2^2} =\frac{832}{16^2} =\frac{832}{256} =3.25. \]
- Exceso de curtosis:
\[ \mathrm{kurt\_excess}=\mathrm{kurt}-3=3.25-3=0.25. \]
Conclusión: la curtosis es mayor que 3 (exceso positivo), consistente con colas relativamente más pesadas (hay un valor extremo que domina el cuarto momento).
8.2.1 Gráfica: distribuciones con mismo promedio y dispersiones (curtosis)
En esta gráfica podemos ver como dos variables pueden tener el mismo promedio y la misma dispersión típica, pero una puede generar muchos más valores extremos (colas pesadas), lo que cambia decisiones como: usar mediana/IQR, winsorizar, segmentar, transformar (log) o usar modelos robustos.
rng = np.random.default_rng(202)
n = 6000
mu_target = 2.0
# Normal con var=1
xN = rng.normal(loc=0.0, scale=1.0, size=n)
# Laplace centrada y escalada para var=1 (Var = 2 b^2 => b = 1/sqrt(2))
b = 1/np.sqrt(2)
xL = rng.laplace(loc=0.0, scale=b, size=n)
# t(df=5) escalada para var=1 (Var = df/(df-2))
df = 5
xT = rng.standard_t(df=df, size=n)
xT = xT / np.sqrt(df/(df-2))
# Mismo promedio
xN = xN + mu_target
xL = xL + mu_target
xT = xT + mu_target
def stats_basic(x):
x = np.asarray(x)
mu = x.mean()
m2 = np.mean((x - mu)**2)
m3 = np.mean((x - mu)**3)
m4 = np.mean((x - mu)**4)
skew = m3 / (m2**1.5)
kurt = m4 / (m2**2)
return mu, m2, skew, kurt
muN, varN, skN, kuN = stats_basic(xN)
muL, varL, skL, kuL = stats_basic(xL)
muT, varT, skT, kuT = stats_basic(xT)
print("Resumen (media, var, skew, kurt):")
print(f"Normal : {muN:.3f}, {varN:.3f}, {skN:.3f}, {kuN:.3f}")
print(f"Laplace: {muL:.3f}, {varL:.3f}, {skL:.3f}, {kuL:.3f}")
print(f"t(df=5): {muT:.3f}, {varT:.3f}, {skT:.3f}, {kuT:.3f}")
plt.figure()
plt.hist(xN, bins=70, alpha=0.55, label=f"Normal (kurt={kuN:.2f})")
plt.hist(xL, bins=70, alpha=0.55, label=f"Laplace (kurt={kuL:.2f})")
plt.hist(xT, bins=70, alpha=0.55, label=f"t(df=5) (kurt={kuT:.2f})")
plt.title("Curtosis: misma media (y var≈1), colas distintas")
plt.xlabel("x")
plt.ylabel("Frecuencia")
plt.legend()
plt.tight_layout()
plt.show()Resumen (media, var, skew, kurt):
Normal : 1.979, 1.029, -0.010, 2.933
Laplace: 2.032, 0.964, 0.264, 6.300
t(df=5): 2.006, 0.992, -0.106, 6.092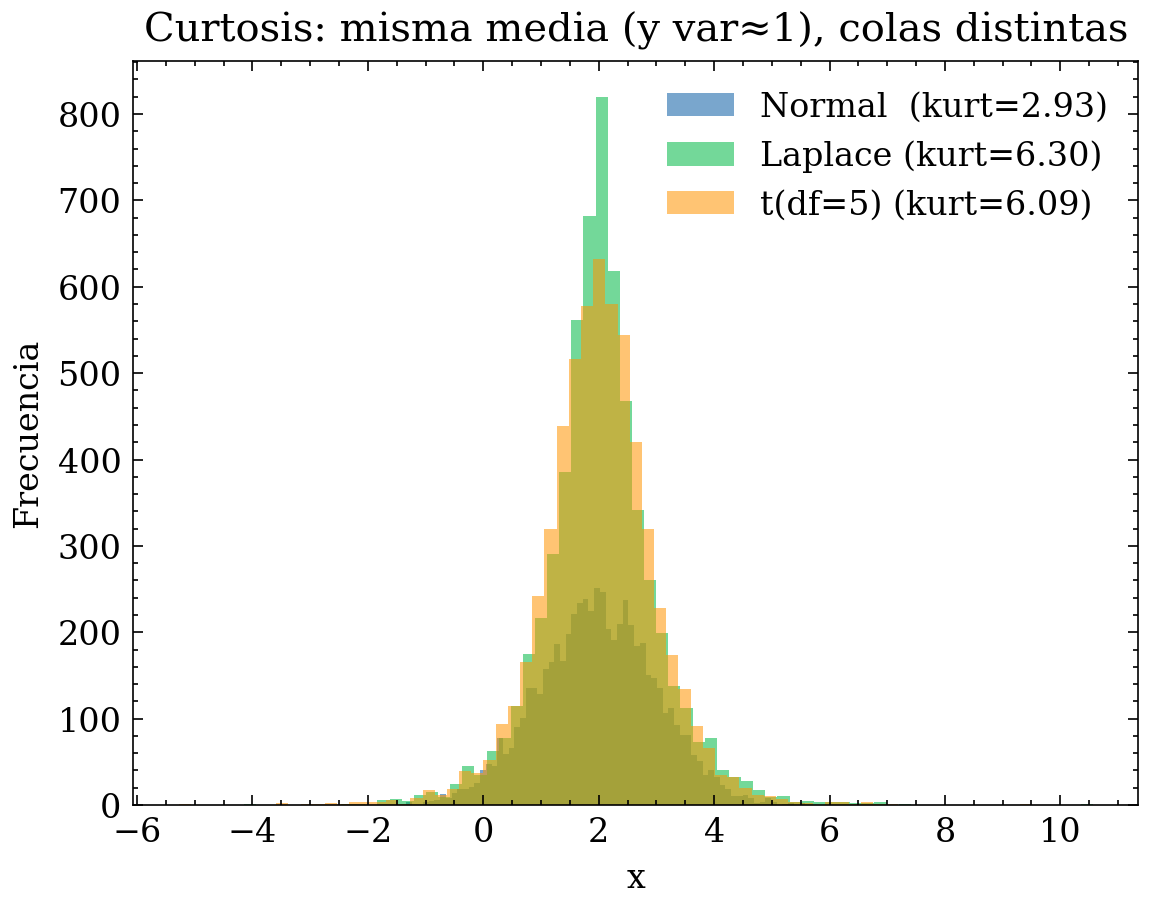
8.3 Comparación final (todas juntas): skewness y kurtosis en un solo vistazo
En este último gráfico se comparan, en la misma escala, cuatro distribuciones representativas: - una simétrica “base” (Normal), - una sesgada (Lognormal reescalada), - una de colas moderadas/pesadas (Laplace), - y una de colas pesadas (t de Student).
rng = np.random.default_rng(404)
n = 7000
# Base simétrica
x_norm = rng.normal(0.0, 1.0, size=n)
# Sesgada (reescalada a media 0, var 1 para comparar forma)
x_logn = rng.lognormal(mean=0.0, sigma=0.65, size=n)
x_logn = (x_logn - x_logn.mean()) / x_logn.std()
# Laplace con var≈1
b = 1/np.sqrt(2)
x_lap = rng.laplace(loc=0.0, scale=b, size=n)
# t(df=3) reescalada a var≈1 (Var = df/(df-2) = 3)
x_t3 = rng.standard_t(df=3, size=n) / np.sqrt(3)
def skew_kurt(x):
x = np.asarray(x)
mu = x.mean()
m2 = np.mean((x - mu)**2)
m3 = np.mean((x - mu)**3)
m4 = np.mean((x - mu)**4)
skew = m3 / (m2**1.5)
kurt = m4 / (m2**2)
return skew, kurt
datasets = [
("Normal", x_norm),
("Lognormal (sesgada)", x_logn),
("Laplace (colas más pesadas)", x_lap),
("t(df=3) (colas pesadas)", x_t3),
]
# 1) Fijar un rango común "razonable" para ver el cuerpo central
# (evita que la cola de t(df=3) aplaste todo)
allx = np.concatenate([x for _, x in datasets])
lo, hi = np.quantile(allx, [0.005, 0.995])
# 2) Figura más ancha + espacio a la derecha para la leyenda
fig, ax = plt.subplots(figsize=(10, 5))
for name, x in datasets:
sk, ku = skew_kurt(x)
ax.hist(
x,
bins=80,
range=(lo, hi),
alpha=0.30,
density=True, # opcional: compara formas (área=1)
label=f"{name} (sk={sk:.2f}, ku={ku:.2f})"
)
ax.set_title("Comparación final: asimetría y curtosis")
ax.set_xlabel("x (escalas comparables)")
ax.set_ylabel("Densidad" if True else "Frecuencia")
# 3) Leyenda fuera del plot
ax.legend(loc="center left", bbox_to_anchor=(1.02, 0.5), frameon=False)
# 4) Ajuste para que no se corte la leyenda
fig.tight_layout()
plt.show()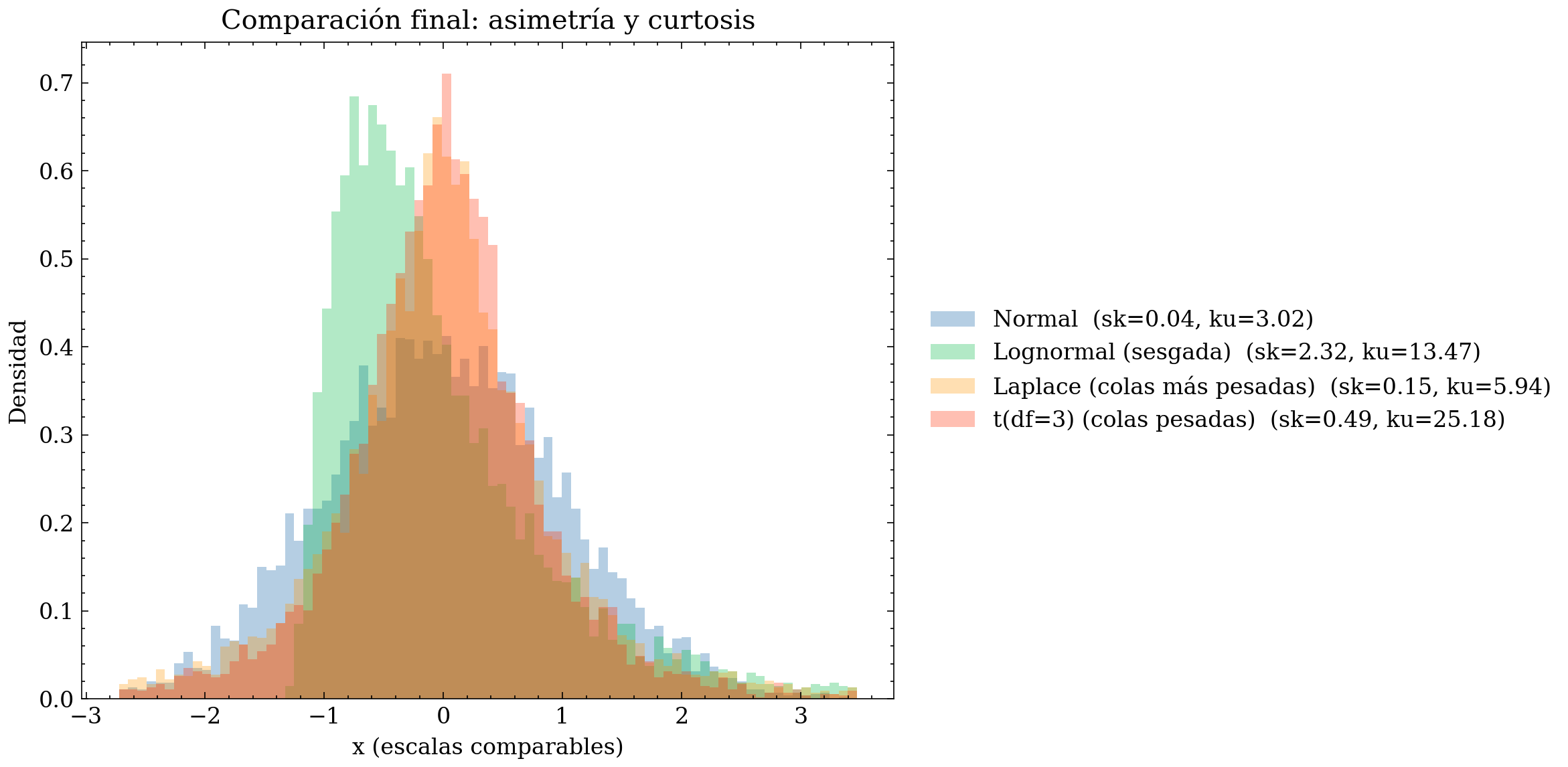
9 Medidas de variabilidad (dispersión)
La variabilidad cuantifica qué tan dispersos están los datos alrededor de una medida de localización (media o mediana). En EDA, medir dispersión no es un lujo: define si una variable aporta señal útil, revela heterogeneidad entre subpoblaciones y anticipa problemas de escala que afectan el entrenamiento de modelos (por ejemplo, gradientes inestables si una variable tiene magnitud mucho mayor que otras). Además, la dispersión es el contexto natural para detectar outliers: un valor “grande” solo es problemático si es grande respecto a la escala típica del conjunto.
9.1 Varianza y desviación estándar
A nivel teórico, la varianza poblacional se define como la expectativa del cuadrado de la desviación respecto a la media:
\[ \sigma^2 \;=\; \mathbb{E}\!\left[(X-\mu)^2\right]. \]
En una muestra \(x_1,\dots,x_n\), la varianza muestral insesgada es:
\[ s^2 \;=\; \frac{1}{n-1}\sum_{i=1}^n (x_i-\bar{x})^2, \qquad s \;=\; \sqrt{s^2}. \]
Interpretación: \(s\) mide la “escala típica” de fluctuación alrededor de \(\bar{x}\). Si \(s\approx 0\), la variable es casi constante; en modelado suele aportar poca información o puede indicar un problema de captura (misma lectura repetida, sensor fijo, campo mal poblado).
Conexión con tratamiento: el escalado estándar (z-score) transforma
\[ z_i \;=\; \frac{x_i-\bar{x}}{s}, \]
lo cual vuelve comparables variables con unidades distintas y estabiliza procedimientos basados en gradiente. Si \(s\) es muy pequeño, este escalado amplifica ruido; en ese caso conviene revisar la variable o usar alternativas (p. ej., eliminarla o escalar por IQR).
9.1.1 Ejemplo gráfico: misma media, distinta desviación estándar (1D)
Caso hipotético: diámetro de tornillos producidos por dos máquinas A y B, ambos con el mismo promedio (cumplen especificación “en promedio”), pero con distinta variabilidad.
Qué aporta al EDA: - Con solo la media no ves el problema: ambas “parecen” correctas. - Con s detectas calidad inconsistente: la máquina con s alto produce más piezas fuera de tolerancia.
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(10)
n = 3000
mu = 5.0
x_small = rng.normal(loc=mu, scale=0.5, size=n)
x_large = rng.normal(loc=mu, scale=2.0, size=n)
plt.figure()
plt.hist(x_small, bins=60, alpha=0.6, label=f"σ≈0.5 (s={x_small.std(ddof=1):.2f})")
plt.hist(x_large, bins=60, alpha=0.6, label=f"σ≈2.0 (s={x_large.std(ddof=1):.2f})")
plt.title("Desviación estándar: misma media, distinta dispersión")
plt.xlabel("x")
plt.ylabel("Frecuencia")
plt.legend()
plt.tight_layout()
plt.show()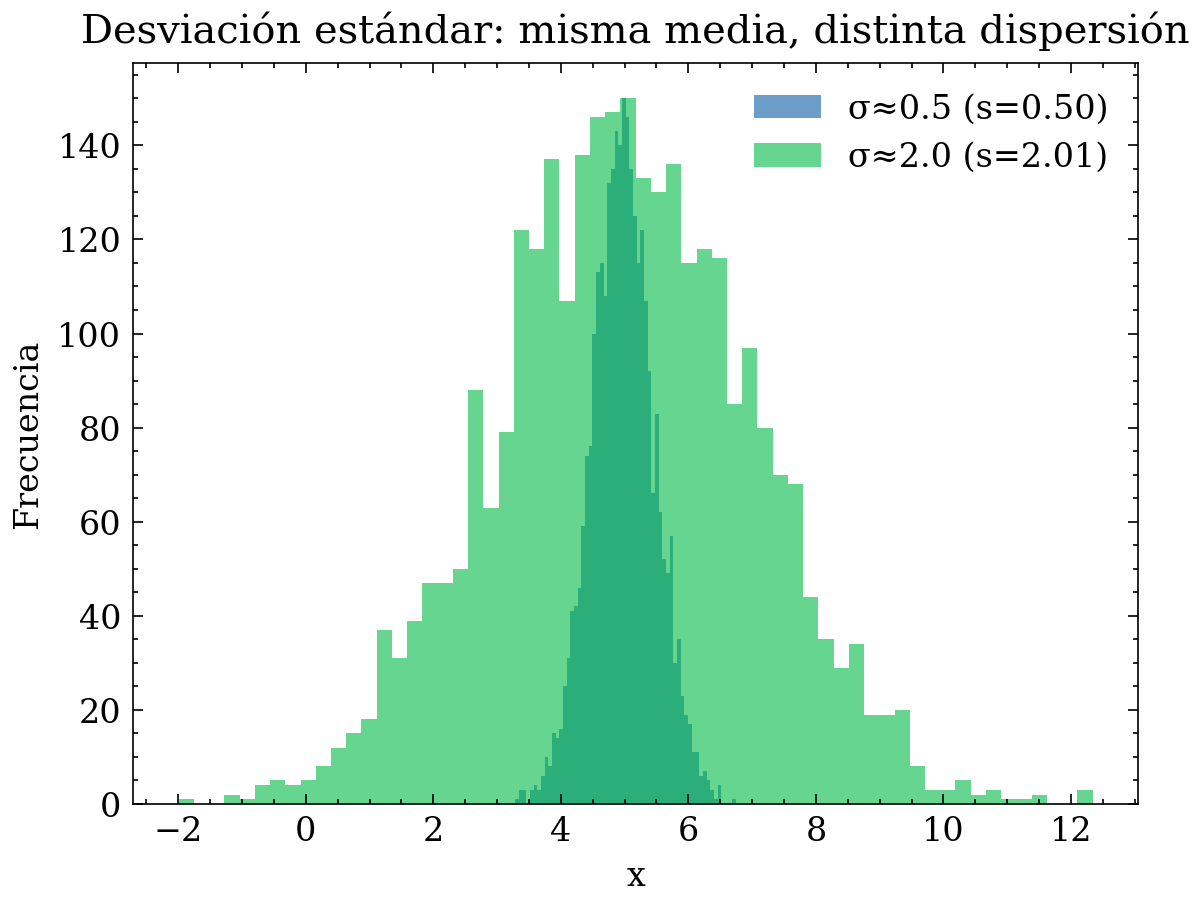
Ejemplo gráfico: dispersión 2D (scatter) controlada por \(s_x, s_y\)
En dos variables \((X,Y)\), la variabilidad se observa como “nube” más o menos extendida. Aquí generamos dos datasets con la misma media pero distinta dispersión.
Caso hipotético: un sensor de temperatura barato vs uno de referencia. Graficas (sensor_barato, sensor_ref).
Qué aporta al EDA: • Si la nube es “gorda” (alta dispersión alrededor de la diagonal), el sensor tiene ruido alto o mala calibración. • Puedes identificar heterocedasticidad: dispersión crece con el valor (peor en temperaturas altas).
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(12)
n = 800
mu_x, mu_y = 0.0, 0.0
# Baja dispersión
x1 = rng.normal(mu_x, 0.6, size=n)
y1 = rng.normal(mu_y, 0.6, size=n)
# Alta dispersión
x2 = rng.normal(mu_x, 2.0, size=n)
y2 = rng.normal(mu_y, 2.0, size=n)
plt.figure()
plt.scatter(x1, y1, s=10, alpha=0.6, label="Baja dispersión")
plt.scatter(x2, y2, s=10, alpha=0.6, label="Alta dispersión")
plt.title("Scatter 2D: efecto de la dispersión en la nube de puntos")
plt.xlabel("X")
plt.ylabel("Y")
plt.legend()
plt.tight_layout()
plt.show()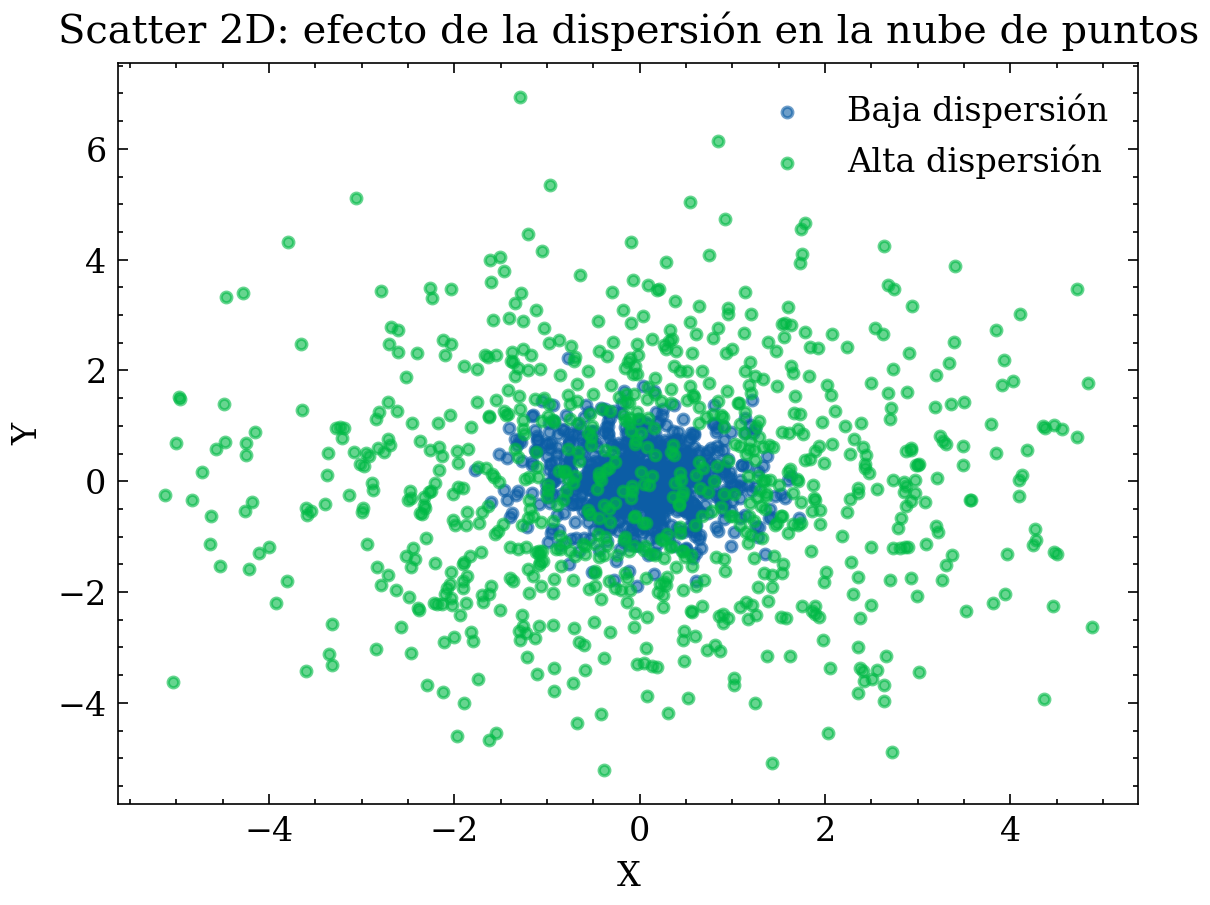
9.2 Cuartiles, Rango e IQR
Los Cuartiles dividen los datos ordenados en cuatro partes de 25% cada una: * \(Q_{0.25}\) (Q1): Primeros 25% de los datos. * \(Q_{0.50}\) (Mediana): El centro de la distribución. * \(Q_{0.75}\) (Q3): El 75% de los datos.
El rango es la diferencia entre el máximo y el mínimo:
\[ R ;=; x_{(n)} - x_{(1)}, \]
donde \(x_{(1)}\le \dots \le x_{(n)}\) son los datos ordenados. El rango es intuitivo pero extremadamente sensible a un solo outlier.
El rango intercuartílico (IQR) usa cuantiles y es más robusto:
\[ \mathrm{IQR} ;=; Q_{0.75} - Q_{0.25}. \]
Limpieza y outliers: una regla robusta clásica marca outliers potenciales si
\[ x < Q_{0.25} - 1.5,\mathrm{IQR} \quad \text{o} \quad x > Q_{0.75} + 1.5,\mathrm{IQR}. \]
La intención no es “borrar por default”, sino activar revisión: ¿error de captura, mezcla de subpoblaciones o caso extremo real?
9.2.1 Ejemplo gráfico: boxplot (IQR) y outliers
Contexto: tiempo de entrega en días. La mayoría llega en 2–5 días, pero hay retrasos extremos (clima, aduana).
Qué aporta al EDA: • Varianza y desviación estándar se inflan por retrasos raros. • El IQR te da la escala “típica” robusta del 50% central. • Si s es enorme pero IQR es pequeño → el fenómeno está dominado por una cola rara (outliers / subpoblación).
Acción: reportar mediana + IQR, segmentar por ruta/proveedor, y tratar extremos por percentiles (P95/P99).
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(21)
base = rng.normal(loc=0.0, scale=1.0, size=600)
out = rng.normal(loc=0.0, scale=1.0, size=8) + 6.0 # extremos
x = np.concatenate([base, out])
q1, q3 = np.quantile(x, [0.25, 0.75])
iqr = q3 - q1
low = q1 - 1.5 * iqr
high = q3 + 1.5 * iqr
plt.figure()
plt.boxplot(x, vert=True)
plt.title(f"Boxplot: IQR={iqr:.2f}, límites [{low:.2f}, {high:.2f}]")
plt.ylabel("x")
plt.tight_layout()
plt.show()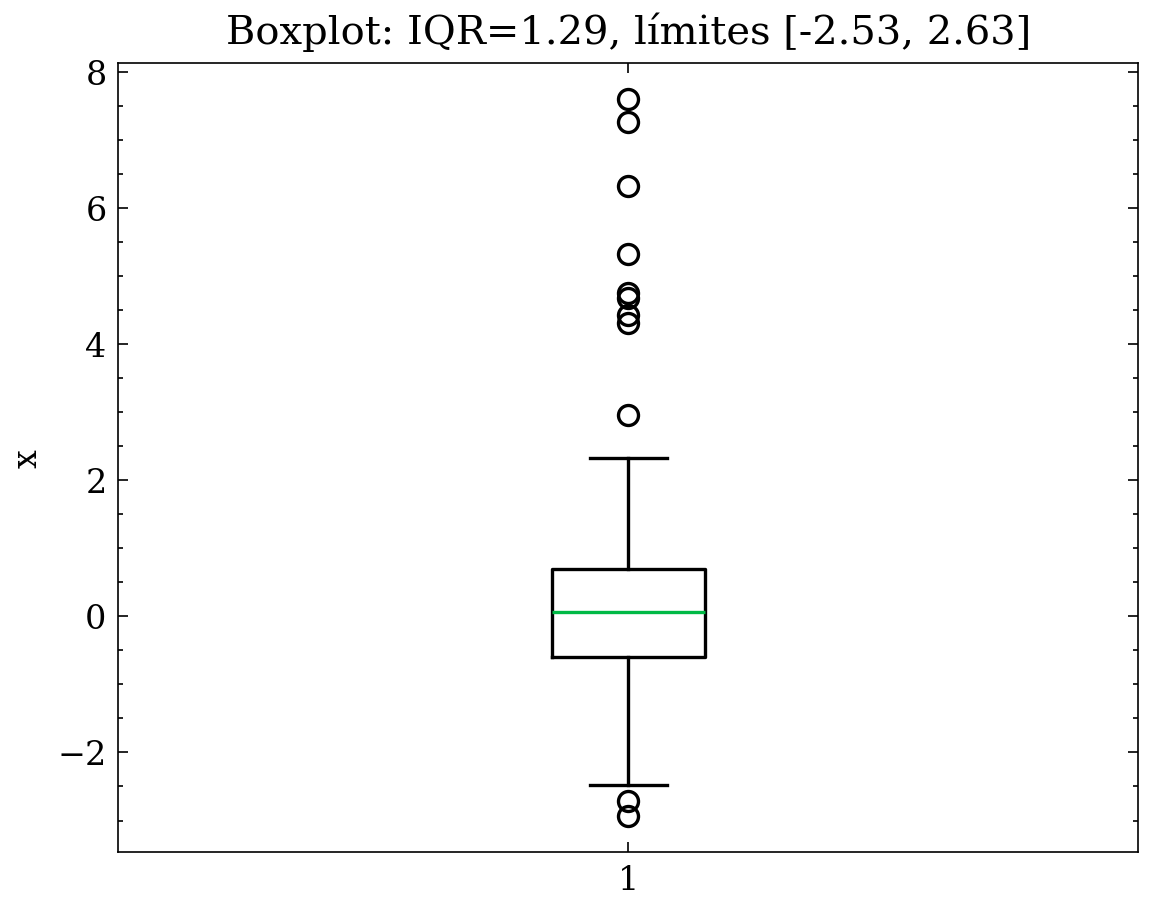
9.3 Coeficiente de variación (CV)
El coeficiente de variación mide dispersión relativa respecto a la media:
\[ \mathrm{CV} ;=; \frac{s}{|\bar{x}|}. \]
Es útil para comparar la variabilidad de variables en escalas distintas (por ejemplo, dispersión relativa de gasto mensual vs. duración de sesiones). Sin embargo, si \(|\bar{x}|\approx 0\), el CV se vuelve inestable y puede explotar numéricamente; en ese caso conviene usar otra normalización (por ejemplo, escalar por mediana o por IQR).
Ejemplo gráfico: dos variables con misma \(s\) pero distinto \(\bar{x}\) (CV distinto)
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(33)
n = 2000
# Misma dispersión, medias muy distintas
a = rng.normal(loc=100.0, scale=10.0, size=n) # CV ~ 0.1
b = rng.normal(loc=5.0, scale=10.0, size=n) # CV grande (media pequeña)
cv_a = a.std(ddof=1) / abs(a.mean())
cv_b = b.std(ddof=1) / abs(b.mean())
plt.figure()
plt.hist(a, bins=60, alpha=0.6, label=f"A: mean={a.mean():.1f}, s={a.std(ddof=1):.1f}, CV={cv_a:.2f}")
plt.hist(b, bins=60, alpha=0.6, label=f"B: mean={b.mean():.1f}, s={b.std(ddof=1):.1f}, CV={cv_b:.2f}")
plt.title("Coeficiente de variación: dispersión relativa")
plt.xlabel("x")
plt.ylabel("Frecuencia")
plt.legend()
plt.tight_layout()
plt.show()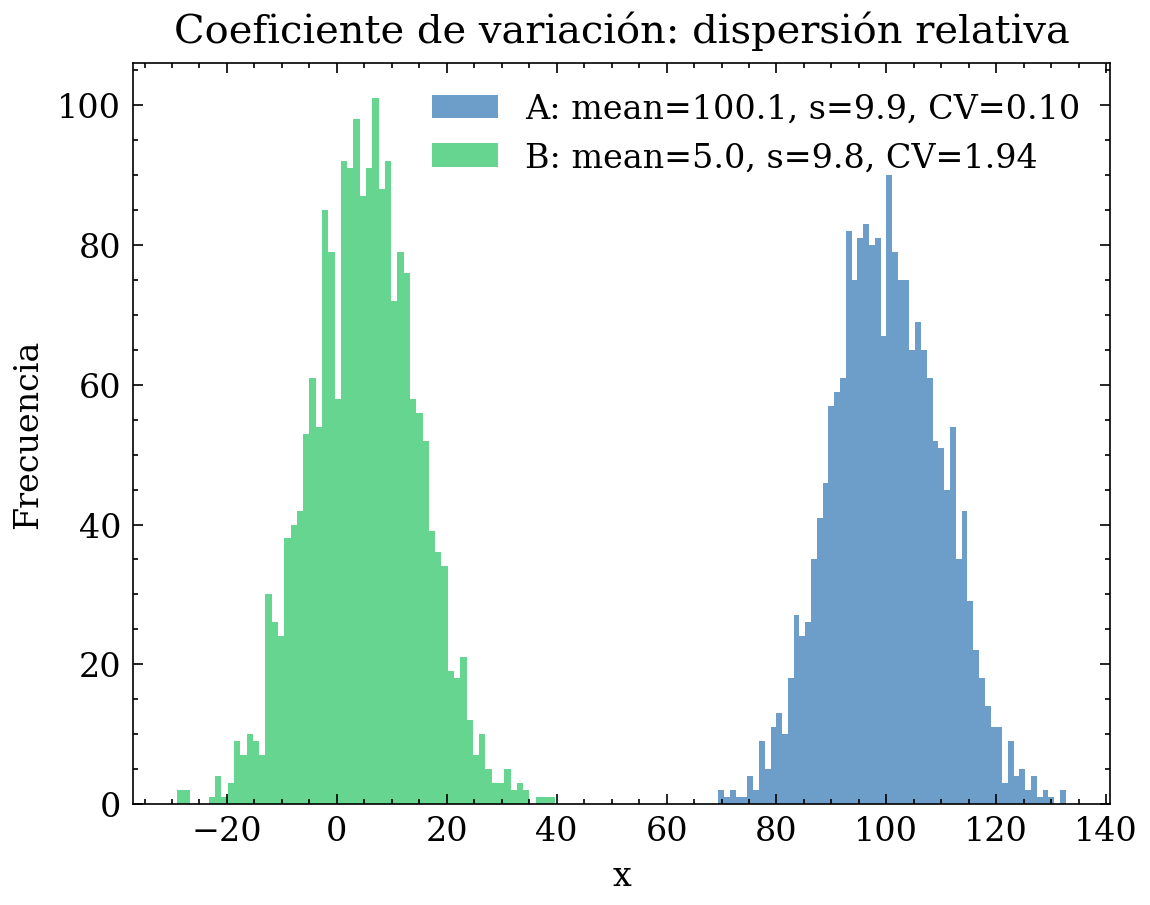
10 Medidas de heterogeneidad (para variables categóricas)
En variables categóricas, la “variabilidad” no se interpreta como dispersión alrededor de una media, sino como heterogeneidad de la distribución: qué tan repartida está la masa de probabilidad entre categorías. Si casi toda la masa cae en una categoría, el atributo es homogéneo (poco informativo); si la masa se reparte entre muchas categorías, el atributo es heterogéneo (potencialmente informativo, pero también puede traer complejidad: alta cardinalidad, categorías raras y riesgo de sobreajuste en codificaciones).
Sea \(p=(p_1,\dots,p_K)\) la distribución empírica sobre \(K\) categorías (con \(p_k \ge 0\) y \(\sum_k p_k = 1\)), donde \(p_k\) se estima como \(p_k=f_k/n\) a partir de frecuencias.
10.1 Entropía de Shannon
La entropía de Shannon mide la incertidumbre promedio al observar una categoría. Se define como:
\[ H(p) \;=\; -\sum_{k=1}^{K} p_k \log p_k. \]
Interpretación formal y práctica:
- \(H(p)\) es máxima cuando \(p\) es uniforme, es decir, \(p_k = 1/K\) para todo \(k\); en ese caso:
\[ H_{\max} \;=\; \log K. \]
- \(H(p)\) es mínima e igual a 0 cuando una categoría domina totalmente (por ejemplo, \(p_1=1\) y \(p_{k\neq 1}=0\)), porque no hay incertidumbre: siempre se observa lo mismo.
A veces es útil reportar entropía normalizada para comparar variables con distinto número de categorías:
\[ H_{\mathrm{norm}}(p) \;=\; \frac{H(p)}{\log K}\in[0,1]. \]
Conexión con tratamiento:
- Entropía muy baja suele indicar que la variable aporta poca segmentación (o que hay una codificación colapsada).
- Entropía alta con muchas categorías raras puede sugerir agrupar niveles infrecuentes en Other, o usar codificaciones que controlen cardinalidad (target encoding con regularización, hashing, etc.), dependiendo del modelo.
10.2 Índice de Gini (impureza)
El índice de Gini (o impureza de Gini, común en árboles de decisión) se define como:
\[ G(p) \;=\; 1-\sum_{k=1}^{K} p_k^2. \]
Interpretación:
- \(\sum_k p_k^2\) es grande cuando la masa está concentrada en pocas categorías; por eso \(G(p)\) aumenta cuando la distribución se vuelve más uniforme.
- Un significado probabilístico útil: \(G(p)\) es la probabilidad de que dos observaciones independientes caigan en categorías distintas. En efecto, si tomas dos observaciones, la probabilidad de que coincidan es \(\sum_k p_k^2\), por lo tanto la probabilidad de que difieran es \(1-\sum_k p_k^2\).
Relación con uniformidad:
- Si \(p\) es uniforme (\(p_k=1/K\)), entonces:
\[ G_{\max} \;=\; 1-\sum_{k=1}^{K}\left(\frac{1}{K}\right)^2 \;=\; 1-\frac{1}{K}. \]
10.3 Ejemplo gráfico: misma \(K\), distinta heterogeneidad (Shannon y Gini)
En este ejemplo se comparan tres distribuciones sobre \(K=6\) categorías: 1) una muy concentrada (una categoría domina), 2) una intermedia, 3) una casi uniforme.
import numpy as np
import matplotlib.pyplot as plt
def entropy(p):
p = np.asarray(p, dtype=float)
p = p[p > 0]
return -np.sum(p * np.log(p))
def gini_impurity(p):
p = np.asarray(p, dtype=float)
return 1.0 - np.sum(p**2)
K = 6
cats = [f"C{k}" for k in range(1, K+1)]
p_conc = np.array([0.85, 0.05, 0.04, 0.03, 0.02, 0.01])
p_mid = np.array([0.40, 0.20, 0.15, 0.10, 0.10, 0.05])
p_uni = np.ones(K) / K
dists = [
("Concentrada", p_conc),
("Intermedia", p_mid),
("Uniforme", p_uni),
]
# Barras para ver masa por categoría
plt.figure()
x = np.arange(K)
width = 0.25
for i, (name, p) in enumerate(dists):
plt.bar(x + (i-1)*width, p, width=width, label=name)
plt.title("Distribuciones categóricas: concentración vs uniformidad")
plt.xlabel("Categoría")
plt.ylabel("Probabilidad empírica $p_k$")
plt.xticks(x, cats)
plt.ylim(0, 1.0)
plt.legend()
plt.tight_layout()
plt.show()
# Comparación en el plano (H, G)
Hs = [entropy(p) for _, p in dists]
Gs = [gini_impurity(p) for _, p in dists]
plt.figure()
plt.scatter(Hs, Gs)
for (name, _), h, g in zip(dists, Hs, Gs):
plt.text(h, g, f" {name}", va="center")
plt.title("Heterogeneidad: Entropía vs Gini")
plt.xlabel("$H(p)$")
plt.ylabel("$G(p)$")
plt.tight_layout()
plt.show()
plt.show()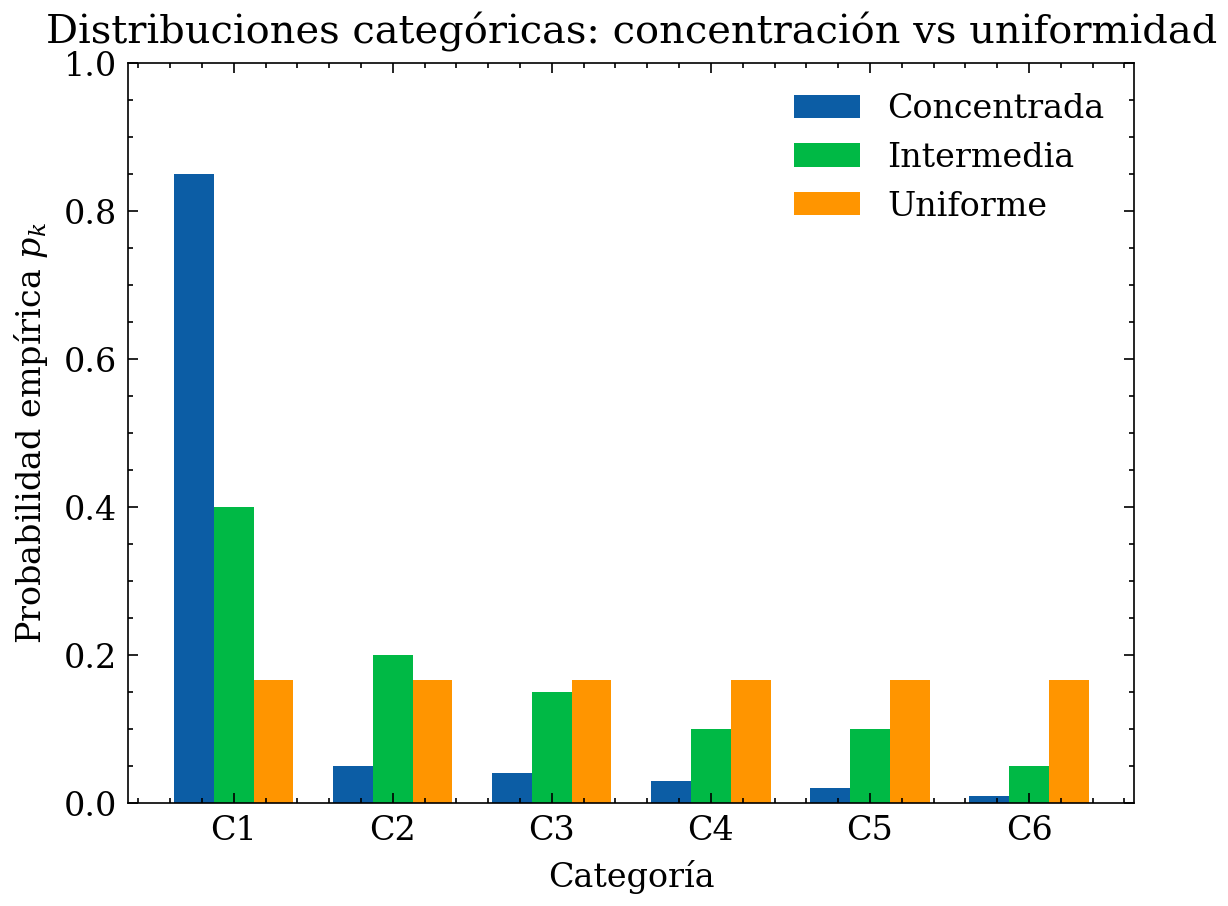
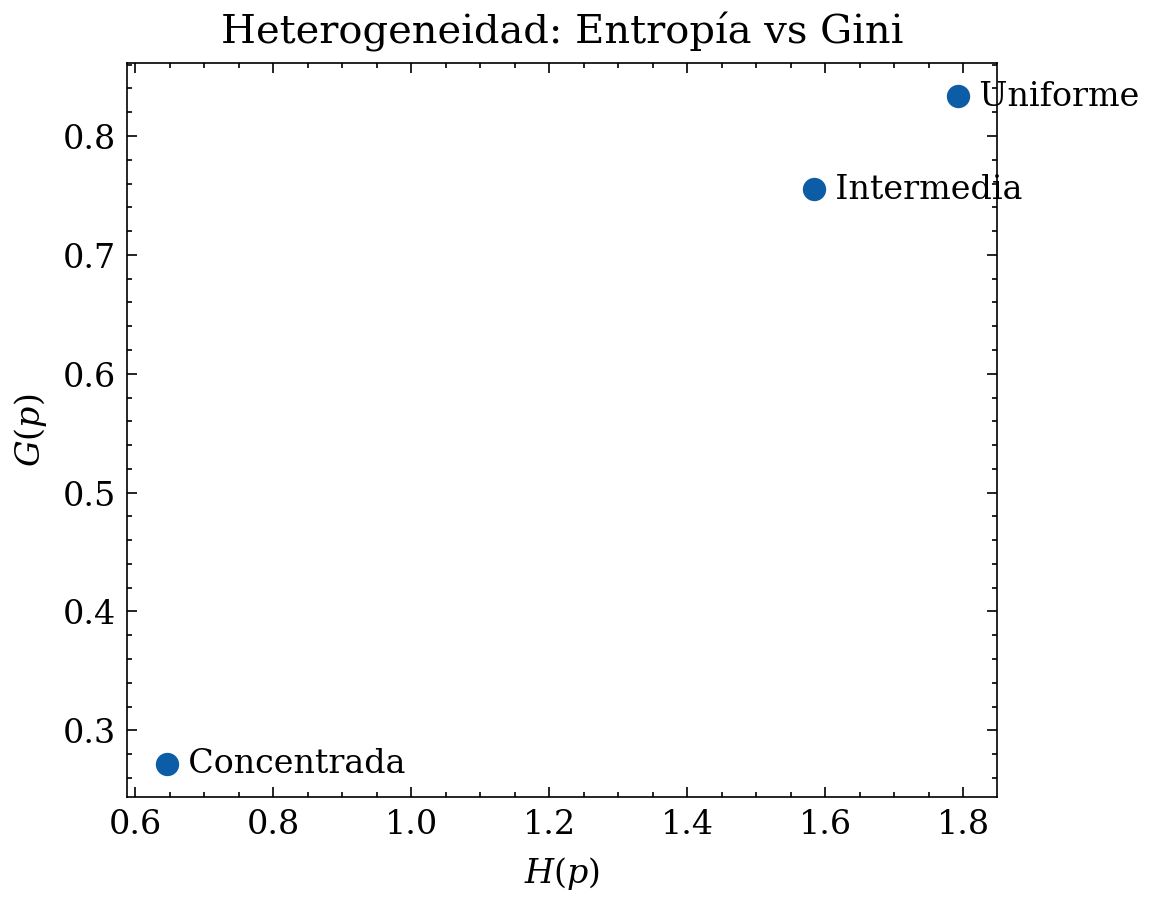
Lectura EDA: - La distribución “concentrada” tiene \(H\) y \(G\) bajos: poca diversidad efectiva, variable poco informativa (o dominada por una etiqueta). - La “uniforme” maximiza \(H\) y casi maximiza \(G\): alta diversidad efectiva, pero puede implicar muchas categorías con baja frecuencia si \(K\) es grande (riesgo de sparsity). - La “intermedia” suele ser la más común en datos reales y suele ser manejable con codificaciones estándar.
11 Medidas de concentración (desigualdad)
Las medidas de concentración cuantifican si la “masa” de una distribución está repartida de forma relativamente uniforme o si, por el contrario, se acumula en pocos niveles (categorías dominantes) o en pocos individuos/observaciones (desigualdad en variables no negativas como ingresos, consumo o ventas). En EDA son útiles porque distinguen entre dos escenarios que pueden verse parecidos con media/varianza: (i) muchos valores moderados vs. (ii) pocos valores enormes que dominan el total. Esta diferencia cambia decisiones de limpieza, escalado y modelado.
En lo que sigue se presentan dos familias: concentración en categorías (HHI) y desigualdad en variables continuas/no negativas (Lorenz–Gini).
11.1 Herfindahl–Hirschman Index (HHI)
Sea \(p=(p_1,\dots,p_K)\) una distribución empírica sobre categorías. El índice de Herfindahl–Hirschman se define como:
\[ \mathrm{HHI} \;=\; \sum_{k=1}^{K} p_k^2. \]
Interpretación:
- \(\mathrm{HHI}\) mide concentración: si una categoría domina, su \(p_k\) es grande y su cuadrado domina la suma.
- Si la distribución es uniforme (\(p_k=1/K\)), entonces:
\[ \mathrm{HHI}_{\min} \;=\; \sum_{k=1}^{K}\left(\frac{1}{K}\right)^2 \;=\; \frac{1}{K}. \]
- Si toda la masa está en una sola categoría (\(p_1=1\)), entonces:
\[ \mathrm{HHI}_{\max} \;=\; 1. \]
Relación con heterogeneidad (Gini impureza): el índice de Gini para categorías (impureza) satisface
\[ G(p) \;=\; 1-\sum_{k=1}^{K} p_k^2 \;=\; 1-\mathrm{HHI}. \]
Uso práctico en EDA:
Un HHI alto puede indicar dominancia (p. ej., un canal de venta absorbe casi todas las transacciones) o un problema de captura/codificación (p. ej., muchas categorías colapsadas en “Otro”). En variables categóricas de alta cardinalidad, HHI ayuda a decidir si conviene agrupar categorías raras o revisar si la distribución está sesgada por diseño de muestreo.
11.2 Curva de Lorenz y coeficiente de Gini (desigualdad)
Para variables no negativas \(x_i \ge 0\) (ingreso, gasto, ventas, duración acumulada), interesa saber si el total se reparte de forma homogénea o si está dominado por pocos casos. Para ello se usa la curva de Lorenz.
- Ordena los datos: \(x_{(1)}\le \dots \le x_{(n)}\).
- Define la fracción acumulada de población
\[ u_i \;=\; \frac{i}{n}, \]
y la fracción acumulada de masa
\[ L(u_i) \;=\; \frac{\sum_{j=1}^{i} x_{(j)}}{\sum_{j=1}^{n} x_{(j)}}. \]
La curva \(L(u)\) compara la distribución real con la línea de igualdad perfecta \(L(u)=u\).
El coeficiente de Gini es el doble del área entre la línea de igualdad y la curva de Lorenz:
\[ \mathcal{G} \;=\; 1 - 2\int_0^1 L(u)\,du. \]
Una forma discreta común (basada en diferencias absolutas) es:
\[ \mathcal{G} \;=\; \frac{\sum_{i=1}^{n}\sum_{j=1}^{n} |x_i-x_j|}{2n^2\bar{x}}. \]
Interpretación:
- \(\mathcal{G}\approx 0\) implica reparto cercano a igualdad (masa distribuida de forma homogénea).
- \(\mathcal{G}\) grande implica desigualdad: pocos valores aportan gran parte del total, típico de colas pesadas.
Conexión con tratamiento: si \(\mathcal{G}\) es alto, suele haber colas pesadas. Esto puede motivar transformación logarítmica, winsorización, o segmentación por percentiles (modelos por tramo), especialmente si el objetivo es estabilidad y robustez.
11.3 Ejemplo gráfico: Lorenz + Gini en distribuciones sintéticas
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(77)
n = 4000
# Tres distribuciones no negativas con diferentes niveles de desigualdad
x_uniform = rng.uniform(0.0, 1.0, size=n) # relativamente "igualitaria"
x_exp = rng.exponential(scale=1.0, size=n) # desigualdad moderada
x_logn = rng.lognormal(mean=0.0, sigma=1.0, size=n) # colas pesadas, alta desigualdad
def lorenz_curve(x):
x = np.asarray(x)
x = x[x >= 0]
x_sorted = np.sort(x)
cum = np.cumsum(x_sorted)
total = cum[-1]
u = np.arange(1, x_sorted.size + 1) / x_sorted.size
L = cum / total if total > 0 else np.zeros_like(cum)
# añadir el punto (0,0) para una curva completa
u = np.concatenate([[0.0], u])
L = np.concatenate([[0.0], L])
return u, L
def gini_from_lorenz(u, L):
# integral aproximada por trapecios
area = np.trapz(L, u)
return 1.0 - 2.0 * area
datasets = [
("Uniform(0,1)", x_uniform),
("Exponencial", x_exp),
("Lognormal", x_logn),
]
plt.figure()
# línea de igualdad perfecta
u_eq = np.linspace(0, 1, 200)
plt.plot(u_eq, u_eq, linestyle="--", label="Igualdad perfecta")
for name, x in datasets:
u, L = lorenz_curve(x)
g = gini_from_lorenz(u, L)
plt.plot(u, L, label=f"{name} (Gini={g:.2f})")
plt.title("Curvas de Lorenz: niveles de desigualdad")
plt.xlabel("Fracción acumulada de población $u$")
plt.ylabel("Fracción acumulada de masa $L(u)$")
plt.xlim(0, 1)
plt.ylim(0, 1)
plt.legend()
plt.tight_layout()
plt.show()/var/folders/0v/g33cdk793lx7s137c8h93w5h0000gn/T/ipykernel_47391/2198729936.py:27: DeprecationWarning: `trapz` is deprecated. Use `trapezoid` instead, or one of the numerical integration functions in `scipy.integrate`.
area = np.trapz(L, u)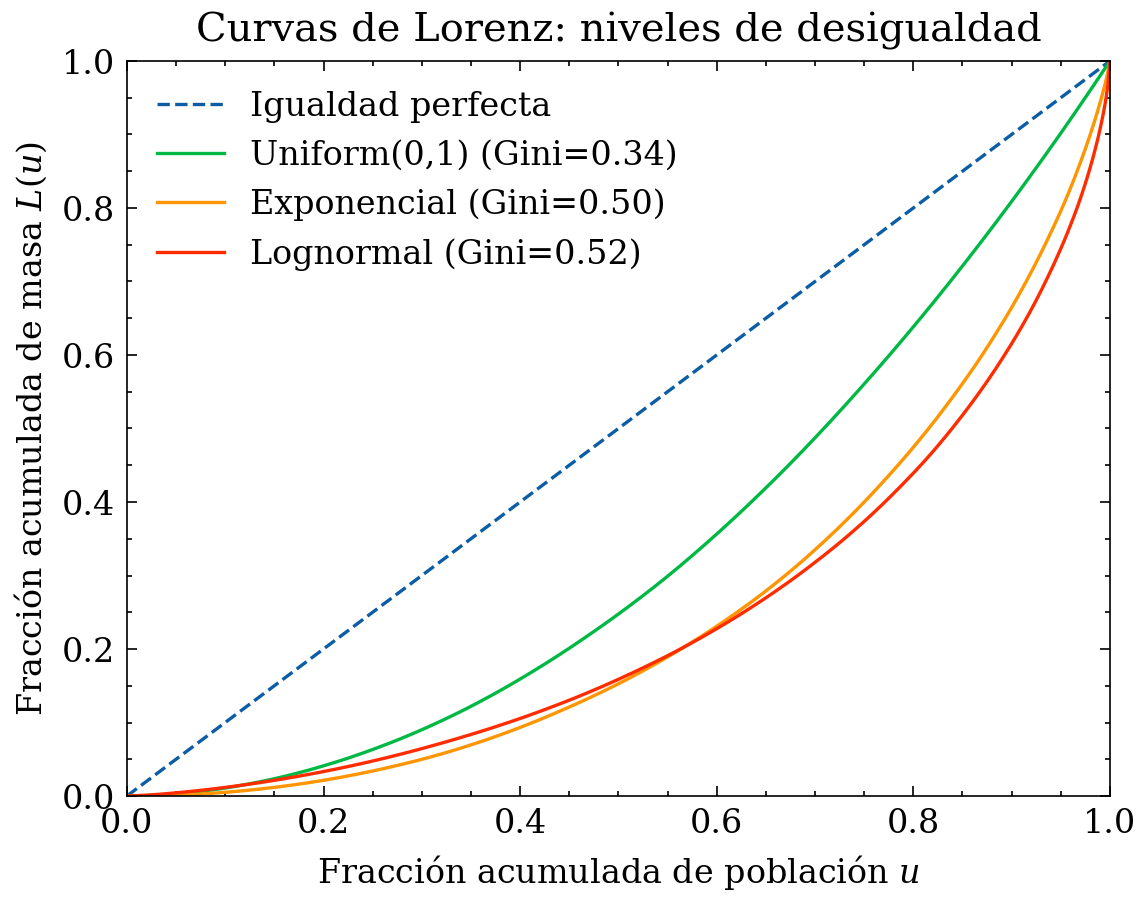
12 Medidas de asociación (correlación) y visualización bivariada
Sí: faltaba una sección de asociación. Solo una precisión conceptual importante: correlación no es “una medida de exploración” separada, sino una familia de medidas bivariadas (o multivariadas) que cuantifican dependencia entre variables. En EDA se usan para detectar relaciones lineales o monótonas, colinealidad, variables redundantes y patrones que sugieren transformaciones o segmentación. Y, como ya vimos, asociación no implica causalidad: la correlación sirve para describir y priorizar hipótesis, no para probar mecanismos.
La correlación se complementa con visualizaciones: el scatterplot revela geometría (no linealidad, heterocedasticidad, outliers, clusters), mientras que un heatmap de correlaciones resume estructura global entre muchas variables.
12.1 Covarianza y correlación de Pearson (dependencia lineal)
Dadas dos variables \(X\) y \(Y\) con muestras \(\{(x_i,y_i)\}_{i=1}^n\), definimos la covarianza muestral (insesgada) como:
\[ s_{XY} \;=\; \frac{1}{n-1}\sum_{i=1}^n (x_i-\bar{x})(y_i-\bar{y}). \]
La correlación de Pearson normaliza la covarianza por las desviaciones estándar:
\[ r_{XY} \;=\; \frac{s_{XY}}{s_X\,s_Y}. \]
Propiedades clave para EDA: - \(r_{XY}\in[-1,1]\). - \(r_{XY}\) mide relación lineal: \(r\approx 0\) no descarta relaciones no lineales. - Si \(s_X\) o \(s_Y\) es muy pequeño (variable casi constante), \(r\) es inestable o indefinido.
Uso típico en limpieza y tratamiento: si hay colinealidad fuerte (|r| cercano a 1), puede haber redundancia; en modelos lineales esto puede causar inestabilidad numérica. También ayuda a detectar errores: correlaciones “imposibles” pueden indicar mezcla de unidades, columnas duplicadas o fugas de información (data leakage).
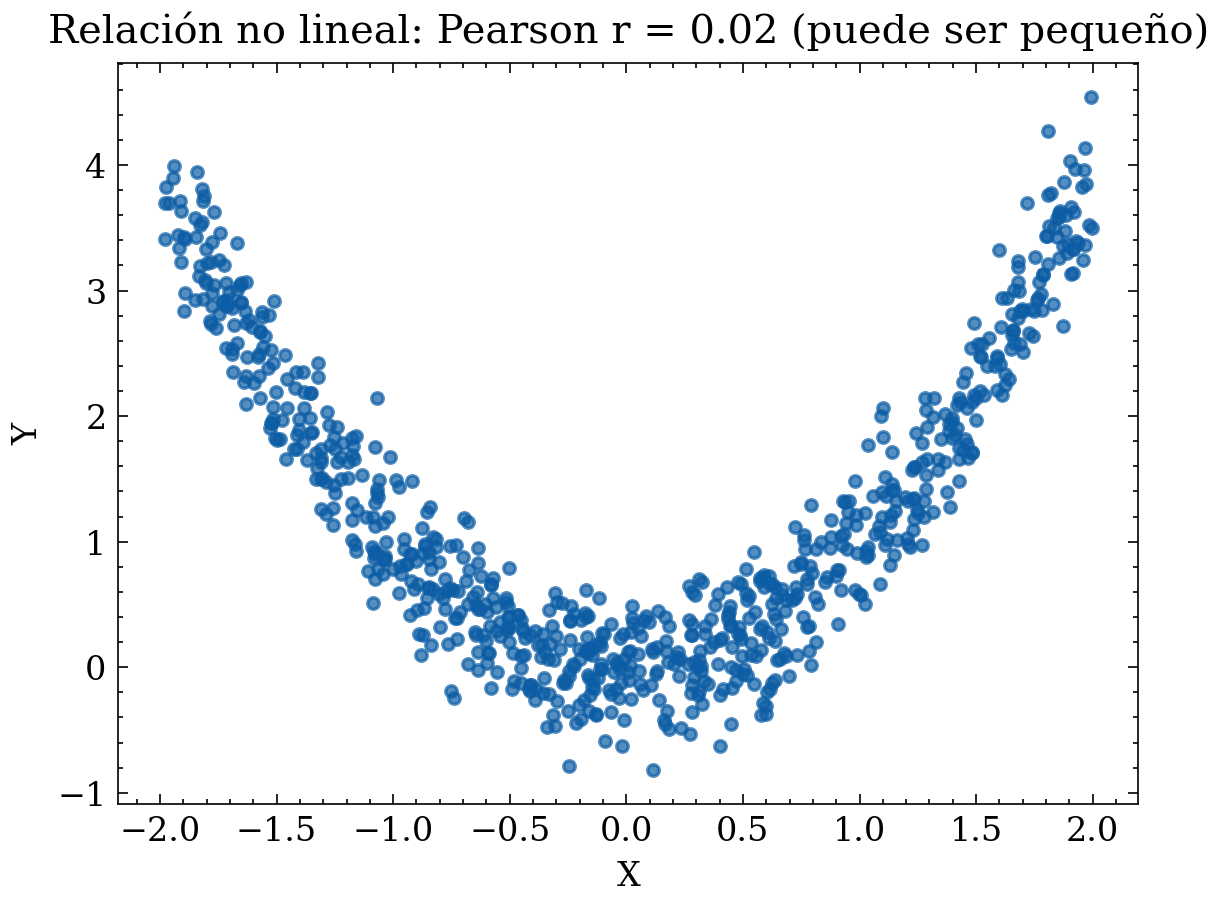
12.1.1 Ejemplo gráfico: correlación alta vs relación no lineal (Pearson puede fallar)
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(9)
n = 800
# Caso 1: relación lineal con ruido
x1 = rng.normal(0, 1, size=n)
y1 = 2.0*x1 + rng.normal(0, 0.6, size=n)
# Caso 2: relación no lineal (parabólica) con ruido
x2 = rng.uniform(-2, 2, size=n)
y2 = x2**2 + rng.normal(0, 0.3, size=n)
r1 = np.corrcoef(x1, y1)[0,1]
r2 = np.corrcoef(x2, y2)[0,1]
plt.figure()
plt.scatter(x1, y1, s=12, alpha=0.7)
plt.title(f"Relación lineal: Pearson r = {r1:.2f}")
plt.xlabel("X")
plt.ylabel("Y")
plt.tight_layout()
plt.show()
plt.figure()
plt.scatter(x2, y2, s=12, alpha=0.7)
plt.title(f"Relación no lineal: Pearson r = {r2:.2f} (puede ser pequeño)")
plt.xlabel("X")
plt.ylabel("Y")
plt.tight_layout()
plt.show()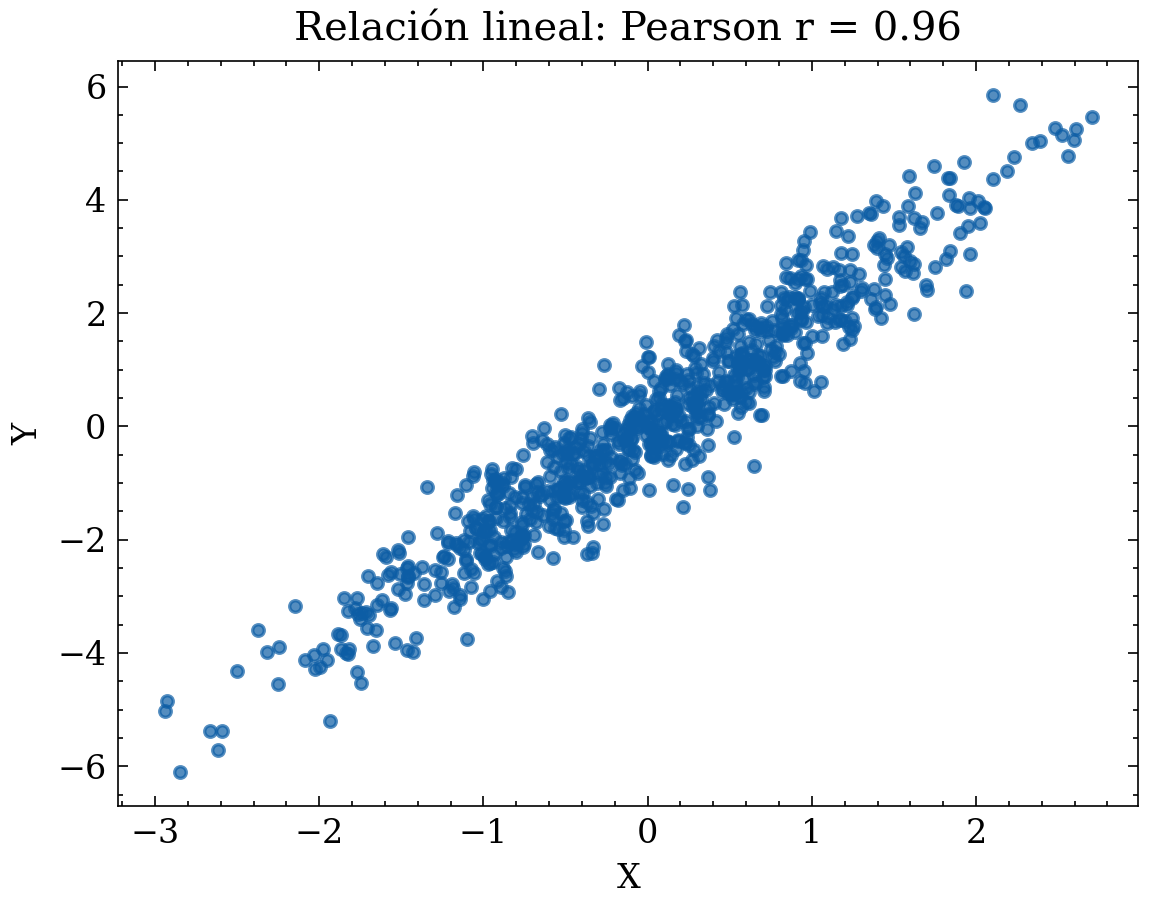
12.1.2 Correlación por rangos: Spearman (dependencia monótona)
Si la relación es monótona pero no lineal, conviene medir correlación sobre rangos. La correlación de Spearman se define como la correlación de Pearson aplicada a los rangos:
\[ \rho_s ;=; \mathrm{corr}(\mathrm{rank}(X),,\mathrm{rank}(Y)). \]
Esta medida es más robusta frente a escalas no lineales y es útil cuando: • la nube es claramente monótona pero curva, • hay outliers que distorsionan Pearson, • las variables son ordinales o discretas con muchos empates (con precauciones).
Ejemplo gráfico: monótona no lineal (Spearman alta, Pearson menor)
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(31)
n = 900
# Monótona no lineal: y = exp(x) + ruido
x = rng.uniform(-2, 2, size=n)
y = np.exp(x) + rng.normal(0, 0.5, size=n)
pearson = np.corrcoef(x, y)[0,1]
# Spearman sin librerías externas: correlación de rangos
rx = np.argsort(np.argsort(x))
ry = np.argsort(np.argsort(y))
spearman = np.corrcoef(rx, ry)[0,1]
plt.figure()
plt.scatter(x, y, s=10, alpha=0.6)
plt.title(f"Monótona no lineal: Pearson r={pearson:.2f}, Spearman ρ={spearman:.2f}")
plt.xlabel("X")
plt.ylabel("Y")
plt.tight_layout()
plt.show()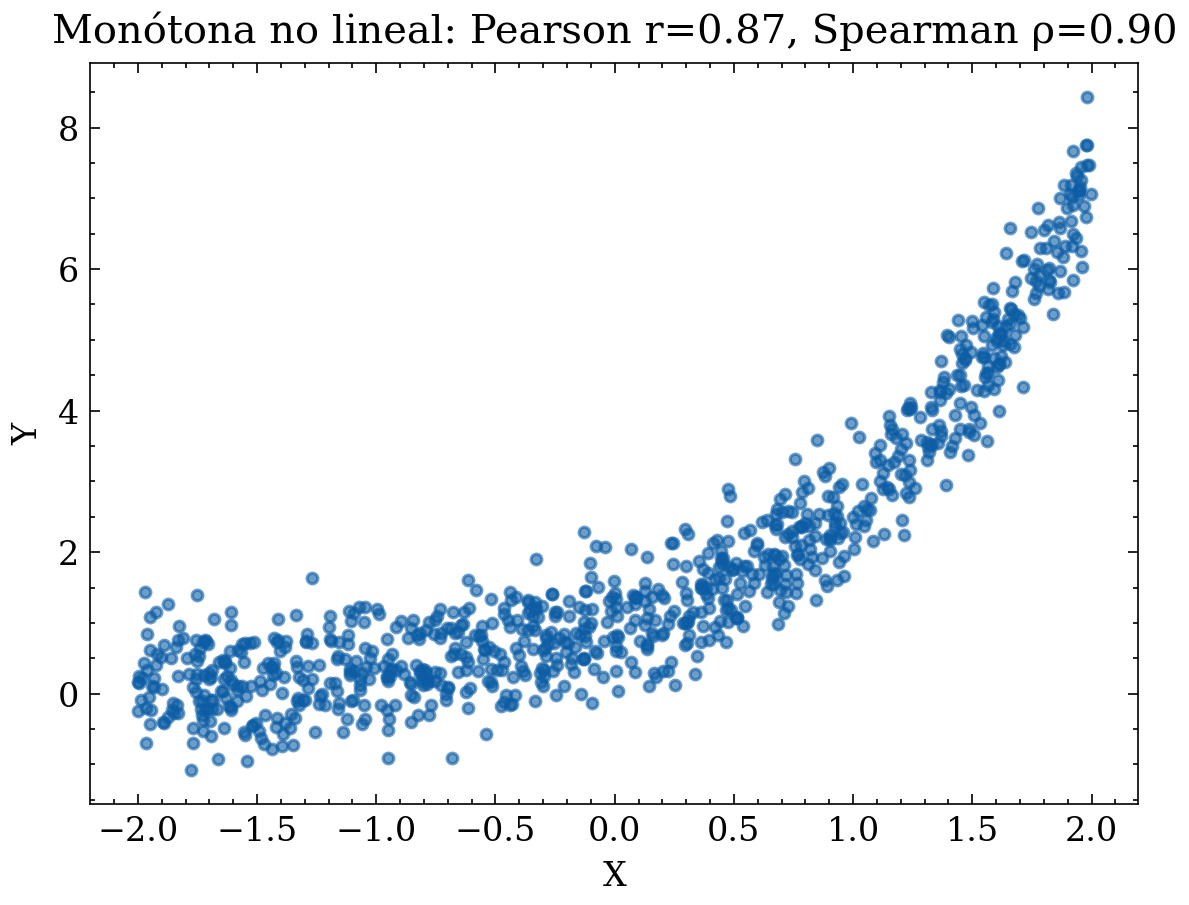
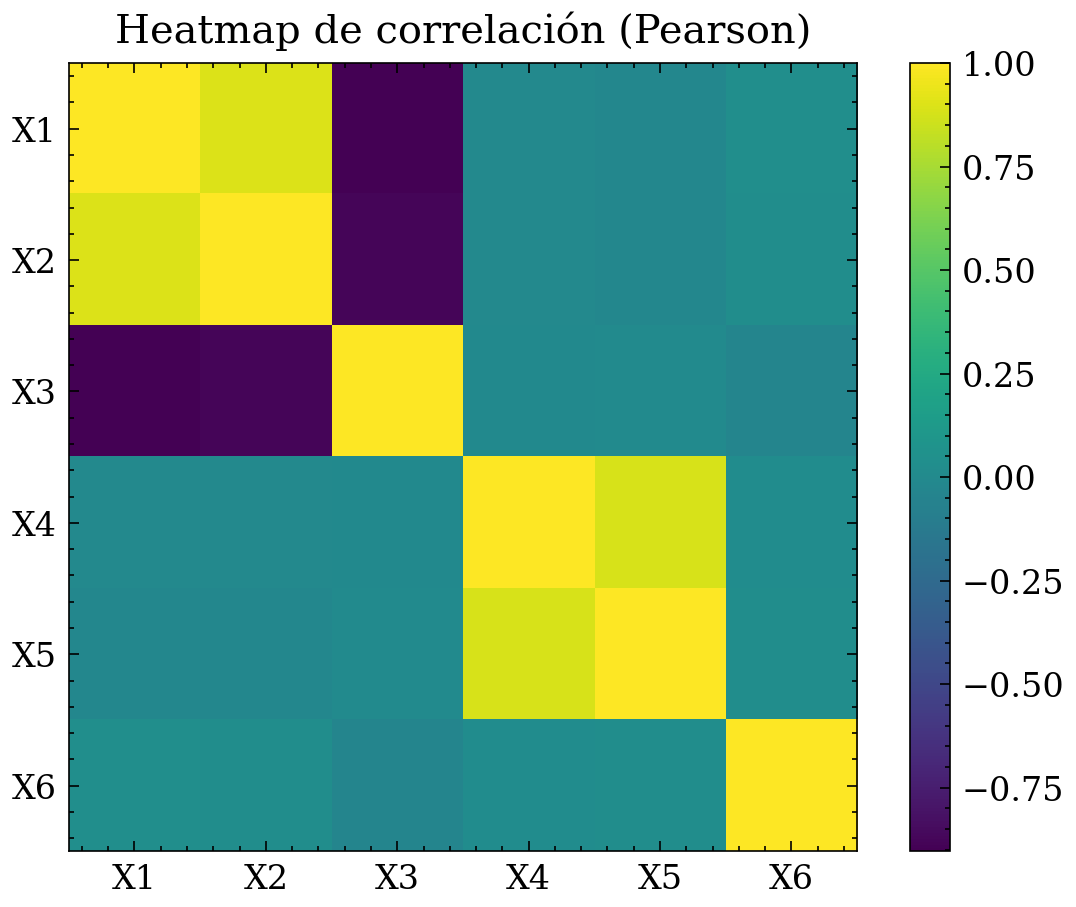
12.1.3 Heatmap de correlaciones (matriz de asociación)
Para muchas variables numéricas \(X_1,\dots,X_p\), se construye la matriz de correlación:
\[ R_{ij} ;=; \mathrm{corr}(X_i, X_j). \]
Un heatmap permite identificar rápidamente: • pares altamente colineales, • bloques de variables relacionadas (estructura tipo “cluster”), • variables casi independientes del resto.
Conexión con limpieza y tratamiento: si aparecen bloques de correlación perfecta o casi perfecta, suele indicar duplicados, fugas (variables derivadas del target), o features redundantes. También ayuda a decidir reducción de dimensionalidad o regularización.
Ejemplo sintético: heatmap con estructura por bloques
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(55)
n = 1200
# Factor común para crear bloque 1
z1 = rng.normal(size=n)
x1 = z1 + rng.normal(scale=0.3, size=n)
x2 = 0.8*z1 + rng.normal(scale=0.3, size=n)
x3 = -0.9*z1 + rng.normal(scale=0.3, size=n)
# Segundo bloque (otro factor)
z2 = rng.normal(size=n)
x4 = z2 + rng.normal(scale=0.3, size=n)
x5 = 0.7*z2 + rng.normal(scale=0.3, size=n)
# Variable casi independiente
x6 = rng.normal(size=n)
X = np.vstack([x1, x2, x3, x4, x5, x6]).T
names = ["X1","X2","X3","X4","X5","X6"]
R = np.corrcoef(X, rowvar=False)
plt.figure()
plt.imshow(R)
plt.title("Heatmap de correlación (Pearson)")
plt.xticks(range(len(names)), names)
plt.yticks(range(len(names)), names)
# Barra de color para interpretar magnitudes
plt.colorbar()
plt.tight_layout()
plt.show()