En una etapa inicial del análisis exploratorio de datos se estudian las medidas de localización y las medidas de variabilidad con el fin de identificar, respectivamente, el comportamiento central de una variable y el grado en que sus observaciones se dispersan alrededor de un valor representativo. Sin embargo, una descripción estadística rigurosa no se agota en estas dos dimensiones. Dos distribuciones pueden compartir una media y una desviación estándar semejantes, y aun así diferir de manera importante en su estructura global. Por ello es necesario incorporar el estudio de la forma de la distribución.
Las medidas de forma permiten caracterizar aspectos tales como la asimetría y el grado de concentración de masa alrededor del centro o en las colas, usualmente descrito mediante la curtosis. En términos aplicados, estas medidas ayudan a responder preguntas como las siguientes: ¿la mayor parte de los productos tiene ventas moderadas con unos cuantos casos excepcionalmente altos?, ¿las observaciones se reparten de forma aproximadamente simétrica?, ¿aparecen colas pesadas o valores extremos frecuentes?, ¿una transformación puede facilitar la interpretación visual y estadística del fenómeno? Además, estas medidas orientan decisiones posteriores del EDA, como la revisión de valores atípicos, la conveniencia de usar medidas robustas o la necesidad de transformar variables para facilitar su análisis.
En este capítulo se estudian las medidas de forma en el dataset de BigMart, utilizando como variable principal Item_Outlet_Sales. No obstante, varias de las herramientas presentadas pueden aplicarse también a otras variables numéricas del conjunto de datos, como Item_MRP, Item_Visibility y Item_Weight.
Preparación del entorno
Trabajaremos con el siguiente dataset BigMart, para esta sección usaremos Python y las bibliotecas pandas, numpy, plotly y matplotlib.
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport plotly.express as pximport plotly.graph_objects as gofrom scipy import statsplt.rcParams["figure.figsize"] = (8, 5)plt.rcParams["axes.grid"] =TrueDATA_PATH ="../../data/bigmart_sales.csv"df = pd.read_csv(DATA_PATH)df.head()
Item_Identifier
Item_Weight
Item_Fat_Content
Item_Visibility
Item_Type
Item_MRP
Outlet_Identifier
Outlet_Establishment_Year
Outlet_Size
Outlet_Location_Type
Outlet_Type
Item_Outlet_Sales
0
FDA15
9.30
Low Fat
0.016047
Dairy
249.8092
OUT049
1999
Medium
Tier 1
Supermarket Type1
3735.1380
1
DRC01
5.92
Regular
0.019278
Soft Drinks
48.2692
OUT018
2009
Medium
Tier 3
Supermarket Type2
443.4228
2
FDN15
17.50
Low Fat
0.016760
Meat
141.6180
OUT049
1999
Medium
Tier 1
Supermarket Type1
2097.2700
3
FDX07
19.20
Regular
0.000000
Fruits and Vegetables
182.0950
OUT010
1998
NaN
Tier 3
Grocery Store
732.3800
4
NCD19
8.93
Low Fat
0.000000
Household
53.8614
OUT013
1987
High
Tier 3
Supermarket Type1
994.7052
Antes de proceder conviene verificar el tipo de las variables y concentrarnos en aquellas que sean cuantitativas.
Cuando \(g_1 > 0\), la cola derecha tiende a ser más extensa; cuando \(g_1 < 0\), domina la cola izquierda; y cuando \(g_1 \approx 0\), la distribución puede considerarse aproximadamente simétrica, aunque esta interpretación siempre debe acompañarse de una inspección gráfica.
Curtosis
La curtosis resume el peso relativo de las colas y la concentración de observaciones alrededor del centro. Una expresión frecuente es:
La resta de 3 permite comparar la distribución con la normal estándar:
si \(g_2 \approx 0\), la curtosis es similar a la de una normal;
si \(g_2 > 0\), la distribución exhibe colas relativamente pesadas y mayor propensión a valores extremos;
si \(g_2 < 0\), las colas son relativamente ligeras y la distribución resulta más plana.
La curtosis no debe leerse únicamente como “pico” central: en la práctica, suele ser más útil interpretarla en términos de presencia de colas pesadas y extremos.
Exploración gráfica inicial de la variable de ventas
Comenzamos con la variable de mayor interés económico: \(\texttt{Item\_Outlet\_Sales}\).
count 8523.000000
mean 2181.288914
std 1706.499616
min 33.290000
25% 834.247400
50% 1794.331000
75% 3101.296400
max 13086.964800
Name: Item_Outlet_Sales, dtype: float64
fig = px.histogram( df, x="Item_Outlet_Sales", nbins=50, marginal="box", title="Distribución de Item_Outlet_Sales")fig.update_layout(bargap=0.05)fig.show()
A partir del histograma y el boxplot, se pueden responder varias preguntas sobre la forma de la distribución.
En primer lugar, no se observa simetría visual. La distribución presenta una clara asimetría positiva (sesgo a la derecha): la mayor parte de las observaciones se concentra en valores relativamente bajos, mientras que una cola se extiende hacia valores de ventas más altos.
En segundo lugar, sí aparecen colas largas, especialmente hacia la derecha. Esto indica que, aunque la mayoría de los productos presenta niveles de ventas moderados, existen algunos casos con ventas considerablemente mayores que el resto.
En tercer lugar, se observan posibles valores extremos, lo cual también se confirma en el boxplot superior, donde varios puntos aparecen fuera de los bigotes. Estos puntos corresponden a observaciones con ventas muy superiores al comportamiento típico.
Finalmente, la gráfica muestra que la masa principal de los datos se concentra en una región relativamente acotada, aproximadamente en el rango bajo y medio de la distribución, mientras que un número reducido de observaciones alcanza valores de ventas mucho más altos. Esto sugiere que el comportamiento típico de las ventas está dominado por valores moderados, pero con algunos productos o combinaciones producto–tienda que generan ventas excepcionalmente elevadas.
Para reforzar la interpretación puede añadirse una curva de densidad aproximada.
import numpy as npimport plotly.graph_objects as gofrom scipy import statsxs = np.linspace(sales.min(), sales.max(), 400)kde = stats.gaussian_kde(sales)fig = go.Figure()# Histograma en densidadfig.add_trace( go.Histogram( x=sales, nbinsx=40, histnorm="probability density", opacity=0.6, name="Histograma" ))# Curva KDEfig.add_trace( go.Scatter( x=xs, y=kde(xs), mode="lines", name="Densidad estimada", line=dict(width=2) ))fig.update_layout( title="Histograma y densidad estimada de Item_Outlet_Sales", xaxis_title="Item_Outlet_Sales", yaxis_title="Densidad", bargap=0.02, height=500, width=900)fig.show()
La superposición del histograma con la curva de densidad permite observar con mayor claridad la forma general de la distribución. Mientras el histograma muestra la frecuencia relativa por intervalos, la curva KDE suaviza esa información y ayuda a identificar la concentración principal de los datos, la presencia de asimetría y la posible existencia de colas largas.
Estos umbrales no son absolutos, pero ayudan a construir una primera lectura del fenómeno. En datasets comerciales es frecuente observar asimetría positiva: muchos productos exhiben ventas moderadas, mientras un grupo reducido alcanza ventas muy elevadas.
Comparación de forma en varias variables numéricas
La forma no tiene por qué ser igual en todas las variables del conjunto de datos. Conviene comparar la asimetría y curtosis de todas las columnas numéricas disponibles.
shape_table = pd.DataFrame({"variable": num_cols,"asimetria": [df[c].dropna().skew() for c in num_cols],"curtosis_exceso": [df[c].dropna().kurt() for c in num_cols]}).sort_values("asimetria", key=np.abs, ascending=False)shape_table
La comparación de asimetría y curtosis en exceso muestra que no todas las variables numéricas presentan la misma estructura de forma. En particular, Item_Outlet_Sales exhibe una asimetría positiva de 1.177531 y una curtosis en exceso de 1.615877, mientras que Item_Visibility presenta una asimetría de 1.167091 y una curtosis en exceso de 1.679445. Estos valores sugieren distribuciones con colas derechas largas y una posible presencia de valores extremos, por lo que en ambas variables conviene reforzar el análisis con medidas robustas, boxplots y, si resulta útil, transformaciones como la logarítmica.
En cambio, Item_MRP muestra una asimetría mucho más baja (0.127202) y una curtosis en exceso negativa (-0.889769), mientras que Item_Weight presenta una asimetría de 0.082426 y una curtosis en exceso de -1.227766. Esto sugiere que ambas variables tienen una forma más cercana a la simetría y una distribución relativamente menos influida por colas pesadas.
Por su parte, Outlet_Establishment_Year registra una asimetría negativa de -0.396641 y una curtosis en exceso de -1.205694. Aunque su forma no parece especialmente extrema, esta variable requiere una interpretación adicional debido a su naturaleza temporal, ya que su análisis no debe basarse únicamente en criterios de distribución continua.
En conjunto, estos resultados indican que el EDA debe adaptarse a la forma específica de cada variable y no aplicar una misma lectura descriptiva a todas por igual.
Transformaciones y su efecto sobre la forma
Cuando una variable presenta fuerte asimetría positiva, una transformación logarítmica puede facilitar tanto la visualización como el modelado posterior. En el caso de las ventas, una opción práctica es usar:
\[
y^{\ast} = \log(1+y),
\]
que evita problemas cuando existen observaciones cercanas a cero.
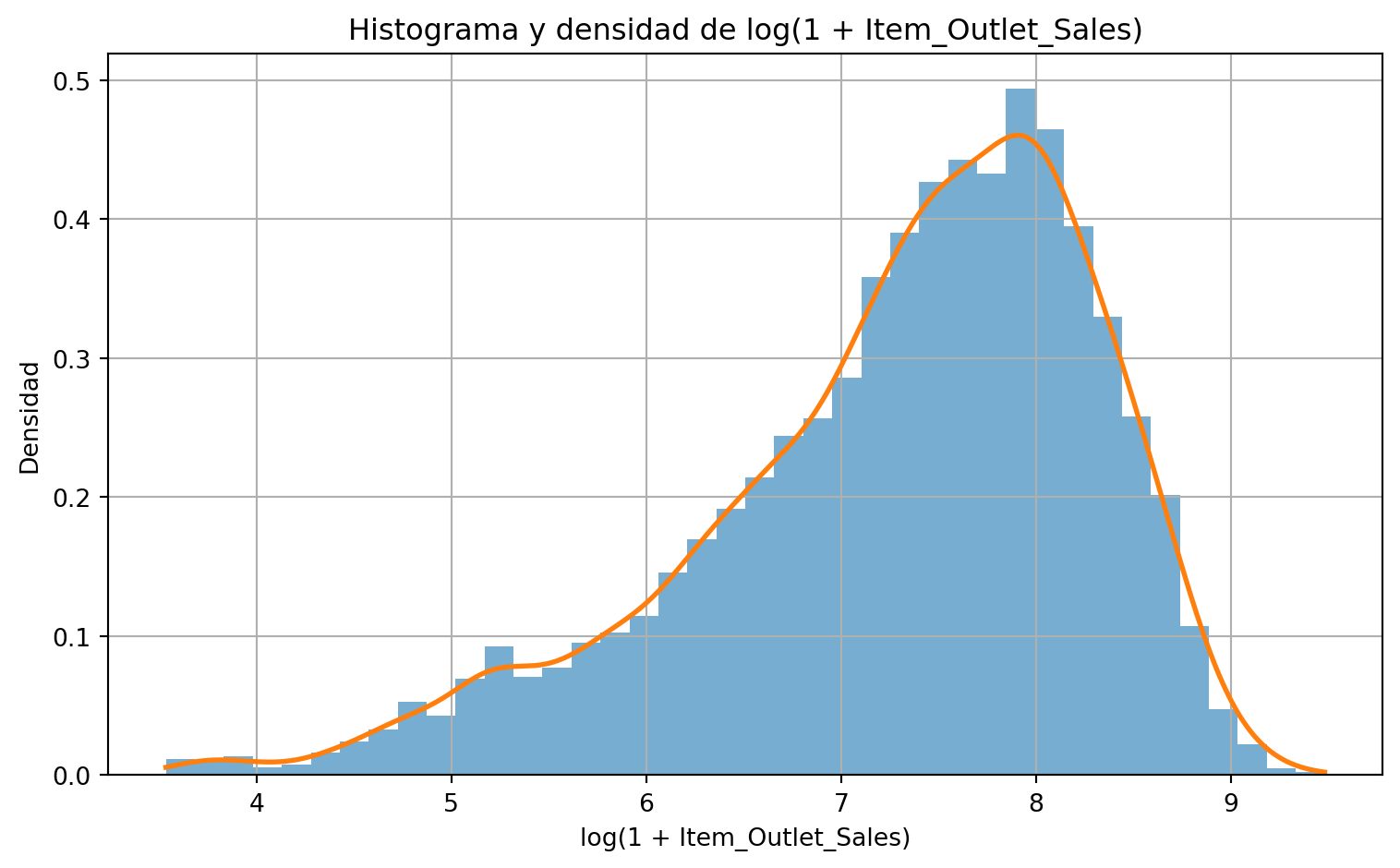
plt.figure()plt.hist(log_sales, bins=40, density=True, alpha=0.6)xs_log = np.linspace(log_sales.min(), log_sales.max(), 400)kde_log = stats.gaussian_kde(log_sales)plt.plot(xs_log, kde_log(xs_log), linewidth=2)plt.title("Histograma y densidad de log(1 + Item_Outlet_Sales)")plt.xlabel("log(1 + Item_Outlet_Sales)")plt.ylabel("Densidad")plt.tight_layout()plt.show()
La comparación entre la variable original y su versión transformada permite mostrar un punto importante del EDA: las medidas de forma no son meramente descriptivas, también orientan decisiones analíticas posteriores. Si la asimetría disminuye sustancialmente bajo la transformación, esto sugiere una representación más equilibrada del fenómeno.
En particular, una transformación logarítmica puede ser útil cuando la distribución presenta una asimetría positiva marcada, es decir, cuando existen valores muy altos que alargan la cola derecha de la distribución. Al aplicar el logaritmo, los valores grandes se comprimen relativamente más que los valores pequeños, lo que tiende a reducir la asimetría y a concentrar mejor los datos alrededor del centro.
Desde el punto de vista del EDA, esta transformación ayuda a:
visualizar mejor la estructura de la distribución, evitando que unos pocos valores muy grandes dominen el gráfico;
comparar observaciones en términos relativos, ya que las diferencias en escala logarítmica representan cambios proporcionales;
reducir la influencia de valores extremos, facilitando una lectura más clara del comportamiento típico de los datos.
Además, esta transformación puede ser útil para análisis posteriores, especialmente cuando se emplean métodos estadísticos o modelos que funcionan mejor con distribuciones más simétricas o con variabilidad más estable. En contextos de modelado, por ejemplo, trabajar con una variable transformada puede mejorar la interpretación de los resultados, estabilizar la varianza y facilitar el ajuste de modelos lineales o regresiones.
En síntesis, el uso del logaritmo en el EDA no solo mejora la interpretación visual de distribuciones muy asimétricas, sino que también prepara los datos para etapas posteriores del análisis, donde una representación más equilibrada de la variable puede resultar analíticamente más conveniente.
Gráfico cuantil-cuantil como apoyo visual
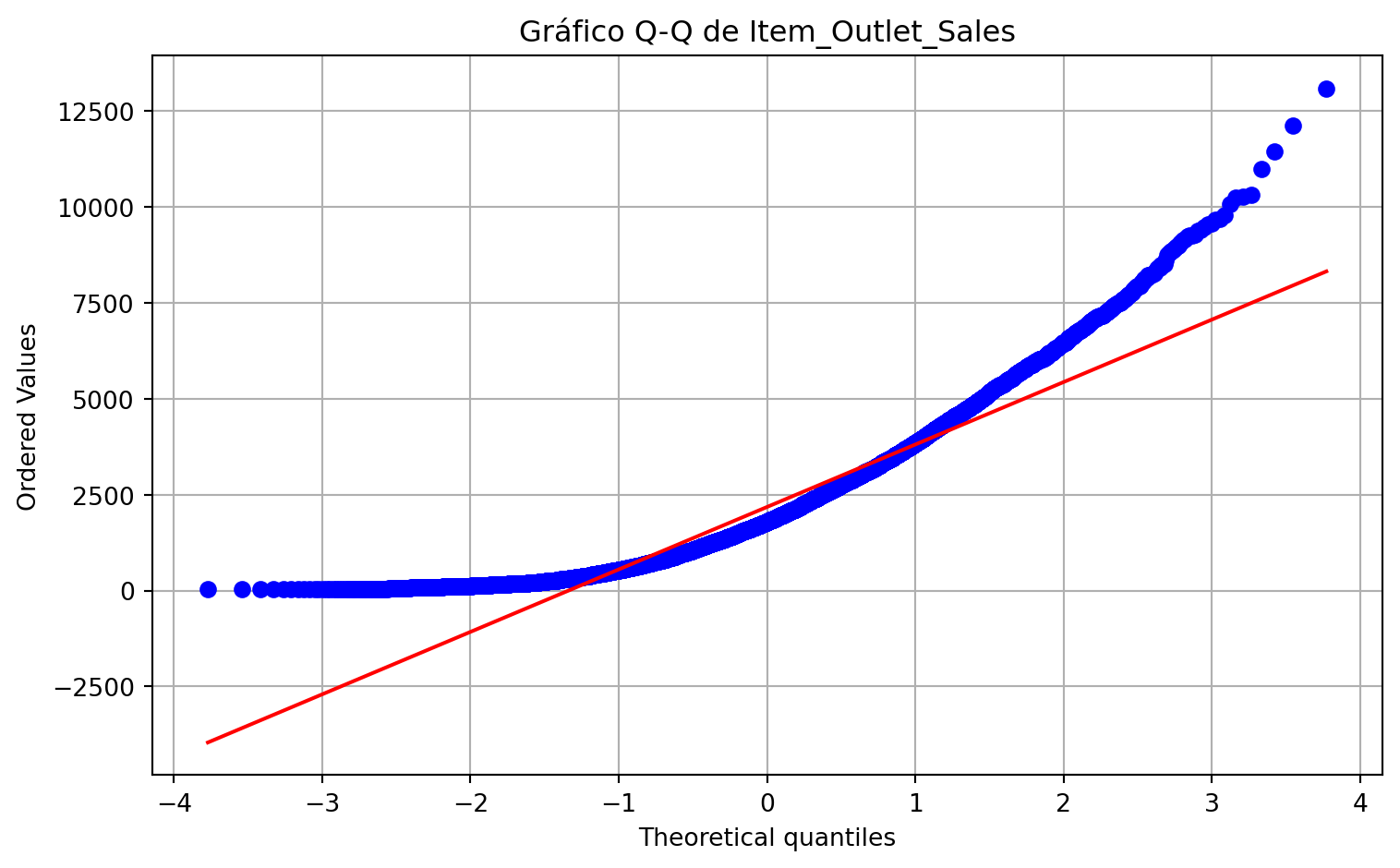
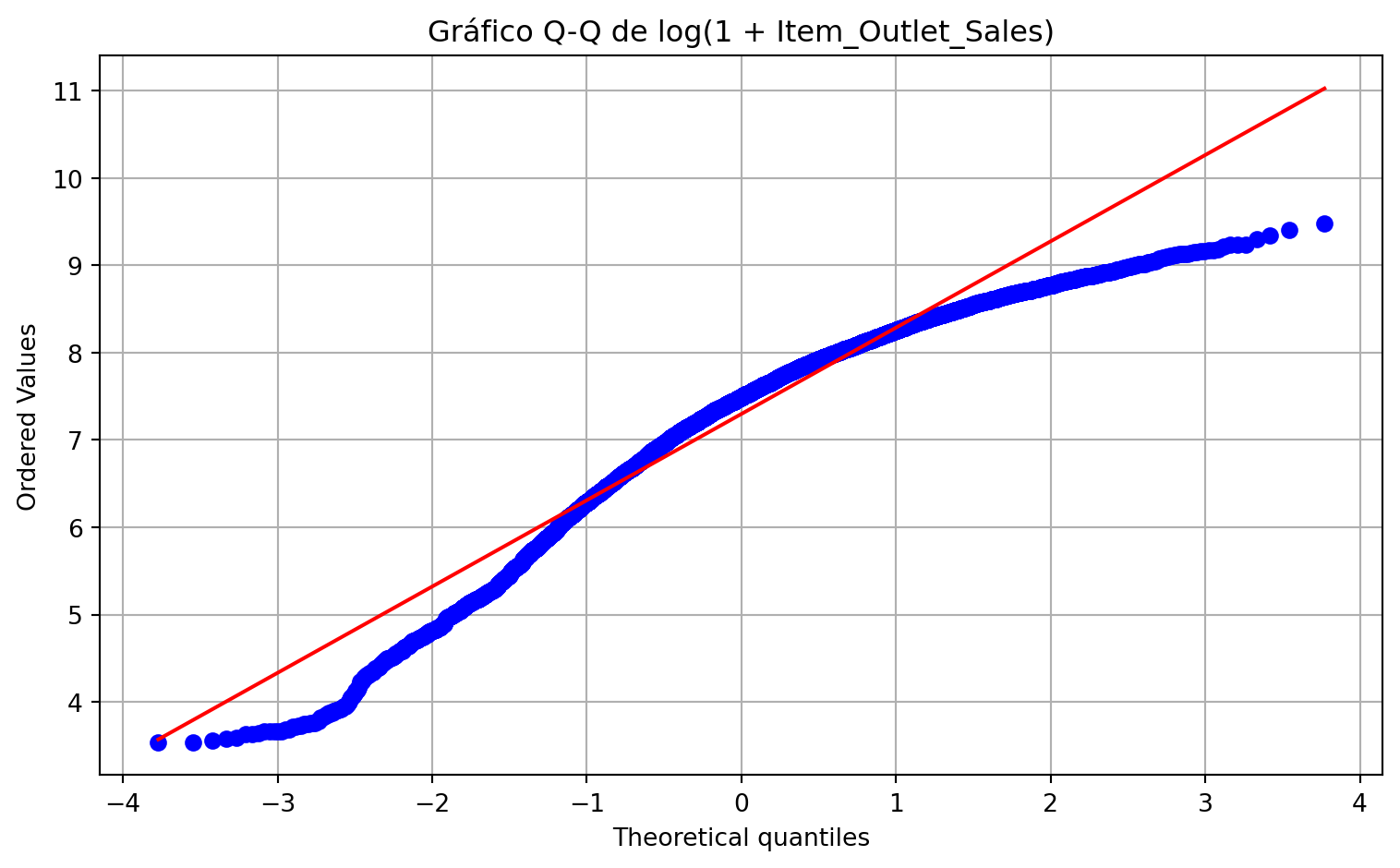
Otra herramienta útil para estudiar la forma es el gráfico Q-Q frente a la distribución normal. No debe interpretarse como una prueba definitiva, pero sí como un recurso visual para detectar desviaciones sistemáticas respecto a simetría y colas gaussianas.
plt.figure()stats.probplot(sales, dist="norm", plot=plt)plt.title("Gráfico Q-Q de Item_Outlet_Sales")plt.tight_layout()plt.show()
plt.figure()stats.probplot(log_sales, dist="norm", plot=plt)plt.title("Gráfico Q-Q de log(1 + Item_Outlet_Sales)")plt.tight_layout()plt.show()
Si la versión transformada se alinea mejor con la recta de referencia que la variable original, ello aporta evidencia visual de una mejora en la regularidad de la forma, aunque no implica normalidad perfecta.
Mini-dashboard de forma
La siguiente sección integra un dashboard simple para resumir la forma de la variable de ventas y su transformación.