---
title: "Clasificación y árboles de decisión"
author: "Diego Villalba"
date: today
lang: es
format:
html:
toc: true
toc-depth: 3
toc-title: "Contenido"
number-sections: true
code-fold: true
code-tools: true
code-summary: "Mostrar código"
fig-align: center
theme: cosmo
highlight-style: github
smooth-scroll: true
pdf:
toc: true
toc-depth: 3
number-sections: true
documentclass: scrbook
papersize: letter
fontsize: 11pt
geometry: margin=2.5cm
keep-tex: false
execute:
echo: true
warning: false
message: false
cache: false
bibliography: referencias_clasificacion_arboles.bib
crossref:
fig-title: "Figura"
tbl-title: "Tabla"
eq-prefix: "Ec."
---
## Introducción
La clasificación es una de las tareas fundamentales del aprendizaje supervisado. Su objetivo es aprender, a partir de ejemplos previamente observados, una regla de decisión capaz de asignar una etiqueta categórica a nuevas observaciones. A diferencia de la predicción de una variable numérica, donde la salida pertenece a un conjunto continuo o discreto ordenado, en clasificación la salida pertenece a un conjunto finito de clases: por ejemplo, `spam` o `no spam`, `aprobar` o `rechazar`, `positivo`, `negativo` o `neutral` [@hastie2009elements; @james2021introduction].
En términos generales, un problema de clasificación parte de un conjunto de datos de entrenamiento compuesto por pares
$$
\mathcal{D} = \{(\mathbf{x}_i, y_i)\}_{i=1}^{n},
$$
donde $\mathbf{x}_i \in \mathcal{X}$ representa las variables predictoras u observaciones disponibles, mientras que $y_i \in \mathcal{Y}$ representa la clase asociada. El objetivo es construir una función
$$
\hat{f}: \mathcal{X} \to \mathcal{Y}
$$
que generalice razonablemente bien a datos no vistos.
En este capítulo se estudian los árboles de decisión como modelos de clasificación interpretables. El desarrollo se concentra en la lógica general de construcción de árboles, el algoritmo de Hunt, el algoritmo ID3, la entropía, la ganancia de información y la extracción de reglas de clasificación. Estos contenidos reorganizan y amplían las ideas centrales de la presentación de clase sobre clasificación y árboles de decisión.
## Clasificación como problema supervisado
En un problema de clasificación se dispone de ejemplos históricos donde la clase correcta ya es conocida. El modelo utiliza estos ejemplos para aprender regularidades entre las variables explicativas y la etiqueta objetivo.
Algunos ejemplos típicos son:
- clasificar si un correo electrónico es `spam` o `no spam`;
- decidir si una solicitud de crédito debe ser `aprobada` o `rechazada`;
- identificar si una persona presenta o no hipertensión;
- clasificar un comentario como `positivo`, `negativo` o `neutral`;
- predecir si un cliente comprará o no una computadora.
La distinción entre clasificación y regresión depende del tipo de variable objetivo. Si la salida es categórica, se trata de clasificación. Si la salida es numérica, se trata de regresión o predicción continua.
| Tarea | Tipo de salida | Ejemplo |
|---|---:|---|
| Clasificación | Categoría | Aprobado / Reprobado |
| Regresión | Valor numérico | Temperatura de mañana |
::: {.callout-note appearance=“minimal”}
Definición. Un problema de clasificación supervisada consiste en estimar una función $\hat{f}$ que asigna a cada observación $\mathbf{x}$ una clase $y$ dentro de un conjunto finito de etiquetas $\mathcal{Y}$:
$$
\hat{f}: \mathcal{X} \to \mathcal{Y}, \qquad |\mathcal{Y}| < \infty.
$$ {#eq-classification-function}
:::
## Entrenamiento, prueba y generalización
La clasificación suele dividirse en dos etapas principales: entrenamiento y prueba. Durante el entrenamiento, el algoritmo ajusta sus reglas internas utilizando datos etiquetados. Durante la prueba, el modelo se evalúa sobre datos no utilizados en el ajuste para estimar su capacidad de generalización.
Esta separación es esencial porque un modelo puede memorizar los datos de entrenamiento sin aprender patrones útiles. Este fenómeno se conoce como sobreajuste u *overfitting*. En árboles de decisión, el sobreajuste aparece cuando el árbol crece demasiado y produce particiones muy específicas para casos particulares [@breiman1984classification; @quinlan1986induction].
::: {.callout-note appearance=“minimal”}
Definición. Dado un conjunto de entrenamiento $\mathcal{D}_{\text{train}}$ y un conjunto de prueba $\mathcal{D}_{\text{test}}$, la capacidad de generalización de un clasificador se evalúa estimando su desempeño sobre ejemplos que no fueron usados para ajustar el modelo:
$$
\mathcal{D} = \mathcal{D}_{\text{train}} \cup \mathcal{D}_{\text{test}}, \qquad
\mathcal{D}_{\text{train}} \cap \mathcal{D}_{\text{test}} = \varnothing.
$$ {#eq-train-test-split}
:::
## Preparación de datos antes de construir un clasificador
Antes de entrenar un clasificador, es necesario preparar los datos. La calidad del modelo depende directamente de la calidad de las variables disponibles. Tres tareas frecuentes son la limpieza, la transformación y la reducción de dimensiones.
La limpieza de datos incluye corregir valores imposibles o inconsistentes, como edades negativas, fechas mal formateadas o categorías escritas con variantes ortográficas. También incluye decidir cómo tratar valores faltantes. La transformación de datos incluye codificación de variables categóricas, normalización de variables numéricas y conversión de fechas a representaciones útiles. La reducción de dimensiones consiste en eliminar variables redundantes, irrelevantes o excesivamente ruidosas.
En árboles de decisión, la preparación puede ser menos exigente que en modelos lineales o redes neuronales, porque los árboles toleran variables en escalas distintas. Sin embargo, la calidad de las categorías, la presencia de valores faltantes y el tratamiento de variables continuas siguen siendo factores importantes [@james2021introduction; @geron2022hands].
```{python}
import pandas as pd
clientes = pd.DataFrame({
"ingreso": ["alto", "bajo", "medio", "bajo", "medio"],
"historial_crediticio": ["bueno", "malo", "bueno", "regular", "malo"],
"deudas": ["bajas", "altas", "bajas", "altas", "medias"],
"empleo_estable": ["sí", "no", "sí", "no", "sí"],
"decision": ["aprobar", "rechazar", "aprobar", "rechazar", "rechazar"]
})
clientes
```
El ejemplo anterior representa una tarea de clasificación binaria: decidir si una solicitud de crédito debe aprobarse o rechazarse. Las variables predictoras son categóricas y la etiqueta objetivo es `decision`.
## Árboles de decisión
Un árbol de decisión es un modelo predictivo que organiza decisiones sucesivas en una estructura jerárquica. Cada nodo interno representa una pregunta sobre una variable, cada rama representa una posible respuesta y cada hoja representa una clase final. La predicción de una observación se obtiene recorriendo el árbol desde la raíz hasta una hoja.
Los árboles son especialmente útiles cuando se busca interpretabilidad. A diferencia de modelos más opacos, un árbol puede leerse como un conjunto de reglas condicionales del tipo “si ocurre cierta combinación de condiciones, entonces se predice cierta clase” [@breiman1984classification; @quinlan1993c45].
::: {.callout-note appearance=“minimal”}
Definición. Un árbol de decisión para clasificación es una estructura jerárquica compuesta por nodos internos, ramas y hojas. Cada nodo interno aplica una prueba $h_j(\mathbf{x})$, cada rama corresponde a un resultado de la prueba y cada hoja asigna una clase $c \in \mathcal{Y}$:
$$
T(\mathbf{x}) = c, \qquad c \in \mathcal{Y}.
$$ {#eq-decision-tree}
:::
Los elementos principales de un árbol son:
| Elemento | Descripción |
|---|---|
| Nodo raíz | Primer nodo del árbol; contiene todos los ejemplos antes de dividir. |
| Nodo interno | Nodo donde se evalúa un atributo y se divide el conjunto de datos. |
| Rama | Resultado posible de una prueba aplicada en un nodo. |
| Hoja | Nodo terminal que asigna una clase. |
## Partición de datos en árboles de decisión
El proceso de construcción de un árbol se basa en particionar el conjunto de datos. En cada nodo se elige una variable y se divide el conjunto de ejemplos según sus valores.
Cuando el atributo es categórico, el árbol puede crear una rama por cada categoría. Por ejemplo, si `pronóstico` toma los valores `soleado`, `nublado` y `lluvia`, puede generarse una rama para cada caso. Si el árbol se restringe a divisiones binarias, una categoría puede evaluarse mediante preguntas del tipo “¿el color es rojo?”.
Cuando el atributo es continuo, se requiere seleccionar un punto de corte. Por ejemplo, una variable como `ingreso` puede dividirse en `ingreso <= 25000` e `ingreso > 25000`. Aunque ID3 fue propuesto principalmente para atributos categóricos, extensiones como C4.5 incorporan mecanismos más generales para tratar variables continuas [@quinlan1986induction; @quinlan1993c45].
## Algoritmo de Hunt
El algoritmo de Hunt describe una estrategia recursiva general para construir árboles de decisión. La idea central es simple: si todos los ejemplos que llegan a un nodo pertenecen a la misma clase, el nodo se convierte en hoja. Si no, se elige un atributo para dividir los datos y se repite el procedimiento en cada subconjunto.
Sea $D_t$ el conjunto de ejemplos que llega al nodo $t$. El procedimiento puede resumirse así:
1. Si todos los ejemplos en $D_t$ pertenecen a una misma clase $y$, crear una hoja con etiqueta $y$.
2. Si $D_t$ está vacío, crear una hoja con una clase predeterminada, usualmente la clase mayoritaria del nodo padre.
3. Si los ejemplos pertenecen a distintas clases, elegir una prueba sobre algún atributo.
4. Dividir $D_t$ en subconjuntos según el resultado de la prueba.
5. Aplicar recursivamente el mismo procedimiento a cada subconjunto.
Este enfoque es *top-down*, porque comienza en la raíz y avanza hacia las hojas, y es *divide and conquer*, porque descompone el problema global en problemas más pequeños.
::: {.callout-note appearance=“minimal”}
Definición. Sea $D_t$ el conjunto de ejemplos que llega al nodo $t$. Un nodo es puro si todos los ejemplos en $D_t$ pertenecen a la misma clase:
$$
\exists c \in \mathcal{Y} \; \text{tal que} \; y_i = c \quad \forall (\mathbf{x}_i,y_i) \in D_t.
$$ {#eq-pure-node}
:::
## Criterios de parada
La partición del árbol no puede continuar indefinidamente. Las condiciones más comunes para detener el crecimiento son:
- todos los ejemplos del nodo pertenecen a la misma clase;
- no quedan atributos disponibles para seguir dividiendo;
- el número de ejemplos en el nodo es demasiado pequeño;
- la profundidad máxima permitida del árbol ha sido alcanzada;
- la mejora obtenida por una nueva división es menor que un umbral.
En el caso clásico de ID3, si no quedan atributos y todavía hay ejemplos de distintas clases, se asigna la clase más frecuente del nodo. Esta decisión refleja un principio de mayoría local.
## ID3: selección de atributos mediante ganancia de información
ID3, *Iterative Dichotomiser 3*, es un algoritmo clásico para inducir árboles de decisión. Fue propuesto por Quinlan y utiliza ganancia de información para elegir, en cada nodo, el atributo que mejor separa las clases [@quinlan1986induction].
La intuición es que un buen atributo debe producir subconjuntos más homogéneos que el conjunto original. Para medir esta homogeneidad, ID3 utiliza la entropía, una medida proveniente de la teoría de la información [@shannon1948mathematical].
El algoritmo procede de la siguiente manera:
1. Comienza con todos los ejemplos en el nodo raíz.
2. Calcula la entropía del conjunto actual.
3. Evalúa cada atributo disponible.
4. Para cada atributo, calcula la entropía promedio después de dividir.
5. Selecciona el atributo con mayor ganancia de información.
6. Repite el proceso recursivamente en cada rama.
## Entropía como medida de impureza
La entropía mide el grado de mezcla o incertidumbre de las clases en un conjunto de datos. Si todos los ejemplos pertenecen a la misma clase, la entropía es cero. Si las clases están muy mezcladas, la entropía es alta. En un problema binario, la entropía máxima ocurre cuando ambas clases tienen la misma proporción.
::: {.callout-note appearance=“minimal”}
Definición. Sea $S$ un conjunto de ejemplos con $c$ clases y sea $p_i$ la proporción de ejemplos pertenecientes a la clase $i$. La entropía de $S$ se define como:
$$
H(S) = -\sum_{i=1}^{c} p_i \log_2(p_i).
$$ {#eq-entropy}
:::
La convención usual es considerar que $0\log_2(0)=0$, pues el límite de $p\log_2(p)$ cuando $p \to 0^+$ es cero.
Si $S$ contiene 15 ejemplos, con 9 respuestas `Sí` y 6 respuestas `No`, entonces
$$
p(\text{Sí}) = \frac{9}{15}, \qquad p(\text{No}) = \frac{6}{15}.
$$
Por tanto,
$$
H(S) = -\frac{9}{15}\log_2\left(\frac{9}{15}\right)
-\frac{6}{15}\log_2\left(\frac{6}{15}\right)
\approx 0.971.
$$
```{python}
import numpy as np
def entropy(labels):
values, counts = np.unique(labels, return_counts=True)
probs = counts / counts.sum()
return -np.sum(probs * np.log2(probs))
labels = ["Sí"] * 9 + ["No"] * 6
entropy(labels)
```
## Ganancia de información
La ganancia de información mide cuánto se reduce la entropía después de dividir un conjunto de datos usando un atributo. Si la división produce subconjuntos puros, la ganancia será alta. Si la división apenas cambia la mezcla de clases, la ganancia será baja.
::: {.callout-note appearance=“minimal”}
Definición. Sea $S$ un conjunto de datos y sea $A$ un atributo con valores posibles $v \in \operatorname{Values}(A)$. Si $S_v$ denota el subconjunto de ejemplos cuyo atributo $A$ toma el valor $v$, la ganancia de información se define como:
$$
\operatorname{Gain}(S,A) = H(S) - \sum_{v\in \operatorname{Values}(A)} \frac{|S_v|}{|S|} H(S_v).
$$ {#eq-information-gain}
:::
El primer término, $H(S)$, representa el desorden antes de dividir. El segundo término representa el desorden promedio después de dividir, ponderado por el tamaño de cada subconjunto. Por ello, la ganancia mide la mejora obtenida al usar el atributo $A$.
## Ejemplo: construir un árbol para decidir si se juega béisbol
Consideremos un conjunto de datos donde se desea predecir si se juega o no un partido de béisbol. Las variables son `Pronóstico`, `Temperatura`, `Humedad` y `Viento`. La clase objetivo es `Juega`.
```{python}
import pandas as pd
df = pd.DataFrame({
"Pronóstico": [
"Soleado", "Soleado", "Nublado", "Lluvia", "Lluvia",
"Lluvia", "Nublado", "Soleado", "Soleado", "Lluvia",
"Soleado", "Nublado", "Nublado", "Lluvia", "Soleado"
],
"Temperatura": [
"Caluroso", "Caluroso", "Caluroso", "Templado", "Fresco",
"Fresco", "Fresco", "Templado", "Fresco", "Templado",
"Templado", "Templado", "Caluroso", "Templado", "Fresco"
],
"Humedad": [
"Alta", "Alta", "Alta", "Alta", "Normal",
"Normal", "Normal", "Alta", "Normal", "Normal",
"Normal", "Alta", "Normal", "Alta", "Alta"
],
"Viento": [
"Débil", "Fuerte", "Débil", "Débil", "Débil",
"Fuerte", "Fuerte", "Débil", "Débil", "Débil",
"Débil", "Fuerte", "Débil", "Fuerte", "Débil"
],
"Juega": [
"No", "No", "Sí", "Sí", "Sí",
"No", "Sí", "No", "Sí", "Sí",
"Sí", "Sí", "Sí", "No", "No"
]
})
df
```
Primero calculamos la entropía del conjunto completo.
```{python}
H_total = entropy(df["Juega"])
H_total
```
El conjunto tiene 9 ejemplos con clase `Sí` y 6 ejemplos con clase `No`, por lo que la entropía inicial es aproximadamente $0.971$.
Ahora calculamos la ganancia de información para cada atributo.
```{python}
def information_gain(data, attribute, target):
total_entropy = entropy(data[target])
weighted_entropy = 0.0
for value, subset in data.groupby(attribute):
weight = len(subset) / len(data)
weighted_entropy += weight * entropy(subset[target])
return total_entropy - weighted_entropy
attributes = ["Pronóstico", "Temperatura", "Humedad", "Viento"]
gains = {
attr: information_gain(df, attr, "Juega")
for attr in attributes
}
pd.Series(gains).sort_values(ascending=False)
```
Los valores esperados son aproximadamente:
| Atributo | Ganancia de información |
|---|---:|
| Pronóstico | 0.280 |
| Humedad | 0.186 |
| Viento | 0.145 |
| Temperatura | 0.013 |
Por tanto, el atributo elegido como raíz del árbol es `Pronóstico`, ya que produce la mayor reducción de entropía.
## Construcción de ramas después de elegir la raíz
Una vez elegida la raíz, se construye una rama por cada valor de `Pronóstico`:
- `Pronóstico = Nublado`;
- `Pronóstico = Soleado`;
- `Pronóstico = Lluvia`.
En el subconjunto `Nublado`, todos los ejemplos pertenecen a la clase `Sí`, por lo que esa rama se convierte en una hoja.
```{python}
df[df["Pronóstico"] == "Nublado"]
```
Para la rama `Soleado`, todavía hay mezcla de clases, por lo que se evalúan los atributos restantes: `Temperatura`, `Humedad` y `Viento`.
```{python}
soleado = df[df["Pronóstico"] == "Soleado"]
remaining = ["Temperatura", "Humedad", "Viento"]
pd.Series({
attr: information_gain(soleado, attr, "Juega")
for attr in remaining
}).sort_values(ascending=False)
```
La mayor ganancia se obtiene con `Humedad`. En esta rama se observa que:
- si `Pronóstico = Soleado` y `Humedad = Alta`, entonces `Juega = No`;
- si `Pronóstico = Soleado` y `Humedad = Normal`, entonces `Juega = Sí`.
Para la rama `Lluvia`, se evalúan los atributos restantes. El mejor atributo es `Viento`.
```{python}
lluvia = df[df["Pronóstico"] == "Lluvia"]
pd.Series({
attr: information_gain(lluvia, attr, "Juega")
for attr in remaining
}).sort_values(ascending=False)
```
La regla resultante es:
- si `Pronóstico = Lluvia` y `Viento = Débil`, entonces `Juega = Sí`;
- si `Pronóstico = Lluvia` y `Viento = Fuerte`, entonces `Juega = No`.
## Representación del árbol final
El árbol aprendido puede resumirse como:
```{mermaid}
flowchart TD
A[Pronóstico]
A -->|Nublado| B[Sí]
A -->|Soleado| C[Humedad]
A -->|Lluvia| D[Viento]
C -->|Alta| E[No]
C -->|Normal| F[Sí]
D -->|Débil| G[Sí]
D -->|Fuerte| H[No]
```
Esta representación muestra que el modelo no utiliza todas las variables en todas las ramas. Por ejemplo, en la rama `Nublado` no se requiere revisar `Temperatura`, `Humedad` ni `Viento`, porque la clase ya queda determinada por los ejemplos de entrenamiento.
```{=html}
<div id="id3-root" style="font-family:Georgia,serif;background:#f8f9fb;border:1px solid #d8dee6;border-radius:8px;padding:20px 24px;margin:2em 0;">
<div style="text-align:center;margin-bottom:10px;">
<span style="font-size:1.05em;font-weight:bold;color:#1a2e45;">Algoritmo ID3 — construcción paso a paso</span><br>
<span style="font-size:0.82em;color:#666;">Dataset: ¿Se juega béisbol? · n = 15 ejemplos · 4 atributos</span>
</div>
<div style="text-align:center;margin-bottom:8px;">
<span id="id3-badge" style="background:#1a3a5c;color:#fff;padding:3px 16px;border-radius:12px;font-size:0.8em;"></span>
</div>
<svg id="id3-svg" width="680" height="368" style="display:block;margin:0 auto;overflow:visible;"></svg>
<div id="id3-panel" style="margin:8px 0 6px;padding:10px 14px;background:#fff;border:1px solid #e0e5ed;border-radius:6px;font-size:0.82em;min-height:76px;"></div>
<div id="id3-desc" style="font-size:0.84em;color:#3a3a3a;line-height:1.6;min-height:52px;margin:6px 4px 12px;"></div>
<div style="display:flex;align-items:center;justify-content:center;gap:14px;">
<button id="id3-prev" class="id3btn" onclick="id3Nav(-1)">← Anterior</button>
<span id="id3-ctr" style="font-size:0.82em;color:#666;min-width:80px;text-align:center;"></span>
<button id="id3-next" class="id3btn" onclick="id3Nav(+1)">Siguiente →</button>
</div>
</div>
<style>
.id3btn{padding:5px 16px;border:1px solid #aab;background:#fff;border-radius:4px;cursor:pointer;
font-family:Georgia,serif;font-size:0.82em;transition:background .12s;}
.id3btn:hover{background:#eef2f7;}.id3btn:disabled{opacity:0.38;cursor:default;}
</style>
<script>
(function(){
/* ── nodes & edges (fixed layout) ──────────────────────── */
const N = {
root: {x:340, y:52, lbl:"Pronóstico", t:"int"},
nub_lf: {x:90, y:200, lbl:"Sí", t:"leaf", cls:"si"},
humedad: {x:285, y:200, lbl:"Humedad", t:"int"},
viento: {x:548, y:200, lbl:"Viento", t:"int"},
alta_lf: {x:185, y:335, lbl:"No", t:"leaf", cls:"no"},
norm_lf: {x:385, y:335, lbl:"Sí", t:"leaf", cls:"si"},
deb_lf: {x:462, y:335, lbl:"Sí", t:"leaf", cls:"si"},
fue_lf: {x:635, y:335, lbl:"No", t:"leaf", cls:"no"},
};
// [fromId, toId, label, label-x, label-y]
const E = [
["root", "nub_lf", "Nublado", 186, 112],
["root", "humedad", "Soleado", 307, 108],
["root", "viento", "Lluvia", 459, 108],
["humedad","alta_lf", "Alta", 221, 260],
["humedad","norm_lf", "Normal", 342, 260],
["viento", "deb_lf", "Débil", 497, 260],
["viento", "fue_lf", "Fuerte", 600, 260],
];
/* ── steps ─────────────────────────────────────────────── */
const STEPS = [
{ badge:"Paso 1 de 9", title:"Entropía inicial — nodo raíz",
desc:"ID3 parte con los 15 ejemplos en el nodo raíz. La entropía H(S) = 0.971 indica que el conjunto es impuro: contiene 9 ejemplos «Sí» y 6 «No». En un problema binario, H = 1 es el máximo (clases perfectamente balanceadas) y H = 0 indica nodo puro.",
vN:["root"], vE:[], hl:"root",
panel:{t:"ent", lbl:"Nodo raíz (n = 15)", si:9, no:6, H:0.971}},
{ badge:"Paso 2 de 9", title:"Selección del atributo raíz",
desc:"Se calcula Gain(S, A) para los cuatro atributos. Pronóstico alcanza la mayor ganancia (0.280) gracias a que el subconjunto Nublado es perfectamente puro. Se elige como nodo raíz.",
vN:["root"], vE:[], hl:"root",
panel:{t:"gains", gains:[
{a:"Pronóstico", g:0.280, best:true},
{a:"Humedad", g:0.186},
{a:"Viento", g:0.145},
{a:"Temperatura",g:0.013}]}},
{ badge:"Paso 3 de 9", title:"División por Pronóstico — tres ramas",
desc:"El nodo raíz se divide en tres subconjuntos. Nublado (n = 4) tiene H = 0: todos sus ejemplos son «Sí», por lo que se convierte directamente en una hoja. Los subconjuntos Soleado y Lluvia aún son impuros y deben seguir dividiéndose.",
vN:["root","nub_lf","humedad","viento"], vE:[0,1,2], hl:null,
panel:{t:"sub", subs:[
{lbl:"Nublado (n = 4)", si:4, no:0, H:0.000, pure:true},
{lbl:"Soleado (n = 6)", si:2, no:4, H:0.918, pure:false},
{lbl:"Lluvia (n = 5)", si:3, no:2, H:0.971, pure:false}]}},
{ badge:"Paso 4 de 9", title:"Rama Nublado → hoja pura «Sí»",
desc:"Los 4 ejemplos Nublado pertenecen todos a la clase «Sí». H = 0 → nodo puro. Se crea una hoja. Regla extraída: SI Pronóstico = Nublado → Juega = Sí.",
vN:["root","nub_lf","humedad","viento"], vE:[0,1,2], hl:"nub_lf",
panel:{t:"ent", lbl:"Pronóstico = Nublado (n = 4)", si:4, no:0, H:0.000}},
{ badge:"Paso 5 de 9", title:"Rama Soleado → elegir siguiente atributo",
desc:"Los 6 ejemplos Soleado (2 Sí, 4 No) son impuros (H = 0.918). Se evalúan los atributos restantes. Humedad elimina toda la impureza con ganancia 0.918, la mayor posible en este subconjunto. Se elige Humedad.",
vN:["root","nub_lf","humedad","viento"], vE:[0,1,2], hl:"humedad",
panel:{t:"gains", gains:[
{a:"Humedad", g:0.918, best:true},
{a:"Viento", g:0.294},
{a:"Temperatura",g:0.170}]}},
{ badge:"Paso 6 de 9", title:"División de Humedad en la rama Soleado",
desc:"Soleado + Alta → 4 ejemplos, todos «No» (H = 0). Soleado + Normal → 2 ejemplos, todos «Sí» (H = 0). Ambos subconjuntos son puros: se crean dos hojas. Reglas: SI Soleado ∧ Alta → No; SI Soleado ∧ Normal → Sí.",
vN:["root","nub_lf","humedad","viento","alta_lf","norm_lf"], vE:[0,1,2,3,4], hl:null,
panel:{t:"sub", subs:[
{lbl:"Soleado + Alta (n = 4)", si:0, no:4, H:0.000, pure:true},
{lbl:"Soleado + Normal (n = 2)", si:2, no:0, H:0.000, pure:true}]}},
{ badge:"Paso 7 de 9", title:"Rama Lluvia → elegir siguiente atributo",
desc:"Los 5 ejemplos Lluvia (3 Sí, 2 No) son impuros (H = 0.971). El atributo Viento produce dos subconjuntos perfectamente puros: su ganancia es 0.971, el máximo posible. Se elige Viento.",
vN:["root","nub_lf","humedad","viento","alta_lf","norm_lf"], vE:[0,1,2,3,4], hl:"viento",
panel:{t:"gains", gains:[
{a:"Viento", g:0.971, best:true},
{a:"Humedad", g:0.020},
{a:"Temperatura",g:0.020}]}},
{ badge:"Paso 8 de 9", title:"División de Viento en la rama Lluvia",
desc:"Lluvia + Débil → 3 ejemplos, todos «Sí» (H = 0). Lluvia + Fuerte → 2 ejemplos, todos «No» (H = 0). Ambos subconjuntos puros: se crean las dos hojas finales. Reglas: SI Lluvia ∧ Débil → Sí; SI Lluvia ∧ Fuerte → No.",
vN:["root","nub_lf","humedad","viento","alta_lf","norm_lf","deb_lf","fue_lf"],
vE:[0,1,2,3,4,5,6], hl:null,
panel:{t:"sub", subs:[
{lbl:"Lluvia + Débil (n = 3)", si:3, no:0, H:0.000, pure:true},
{lbl:"Lluvia + Fuerte (n = 2)", si:0, no:2, H:0.000, pure:true}]}},
{ badge:"Paso 9 de 9", title:"Árbol completo — 5 reglas de clasificación",
desc:"El árbol ID3 ha sido construido. Profundidad 2, 5 hojas, 3 de los 4 atributos usados (Temperatura no fue seleccionada en ningún nodo). Todos los nodos hoja son puros. El árbol clasifica correctamente los 15 ejemplos de entrenamiento.",
vN:["root","nub_lf","humedad","viento","alta_lf","norm_lf","deb_lf","fue_lf"],
vE:[0,1,2,3,4,5,6], hl:null,
panel:{t:"rules"}},
];
/* ── SVG helpers ────────────────────────────────────────── */
const svg = document.getElementById('id3-svg');
const NS = "http://www.w3.org/2000/svg";
function mk(tag, attrs, txt) {
const e = document.createElementNS(NS, tag);
for (const [k,v] of Object.entries(attrs)) e.setAttribute(k, v);
if (txt != null) e.textContent = txt;
return e;
}
function drawTree(step) {
svg.innerHTML = '';
const {vN, vE, hl} = step;
// defs for arrowhead
const defs = mk('defs', {});
const marker = mk('marker', {id:'arr', markerWidth:6, markerHeight:6,
refX:5, refY:3, orient:'auto'});
marker.appendChild(mk('path', {d:'M0,0 L0,6 L6,3 z', fill:'#99aabb'}));
defs.appendChild(marker);
svg.appendChild(defs);
// Edges
E.forEach(([fid, tid, lbl, lx, ly], i) => {
if (!vE.includes(i)) return;
const f = N[fid], t = N[tid];
// Clip start to node boundary (approx)
const dx = t.x - f.x, dy = t.y - f.y;
const len = Math.hypot(dx, dy);
const rf = (f.t === 'int') ? (fid === 'root' ? 33 : 28) : 0;
const rt = (t.t === 'int') ? 28 : 16;
const sx = f.x + dx/len*rf, sy = f.y + dy/len*rf;
const ex = t.x - dx/len*rt, ey = t.y - dy/len*rt;
svg.appendChild(mk('line', {
x1:sx, y1:sy, x2:ex, y2:ey,
stroke:'#8899bb', 'stroke-width':1.6,
'marker-end':'url(#arr)'
}));
// Edge label background + text
svg.appendChild(mk('rect', {
x:lx-22, y:ly-9, width:44, height:16, rx:4,
fill:'white', stroke:'#ccd', 'stroke-width':0.8
}));
svg.appendChild(mk('text', {
x:lx, y:ly+4, 'text-anchor':'middle',
'font-size':'10', 'font-family':'Georgia,serif', fill:'#445'
}, lbl));
});
// Nodes
for (const [nid, node] of Object.entries(N)) {
if (!vN.includes(nid)) continue;
const isHL = (nid === hl);
if (node.t === 'int') {
const r = nid === 'root' ? 33 : 28;
svg.appendChild(mk('circle', {
cx:node.x, cy:node.y, r:r,
fill: isHL ? '#2a5285' : '#1a3a5c',
stroke: isHL ? '#f4a03a' : '#0c2040',
'stroke-width': isHL ? 3 : 1.5
}));
// Label (split if long)
svg.appendChild(mk('text', {
x:node.x, y:node.y+5, 'text-anchor':'middle',
'font-size': nid==='root'?'12.5':'11.5',
'font-family':'Georgia,serif', 'font-weight':'bold', fill:'white'
}, node.lbl));
} else {
// Leaf: rounded rect
const w=52, h=30;
const fill = isHL
? (node.cls==='si' ? '#1b5e20' : '#7f0000')
: (node.cls==='si' ? '#2d6a4f' : '#9d0208');
svg.appendChild(mk('rect', {
x:node.x-w/2, y:node.y-h/2, width:w, height:h, rx:7,
fill:fill, stroke: isHL?'#f4a03a':'rgba(0,0,0,0.18)',
'stroke-width': isHL?3:1
}));
svg.appendChild(mk('text', {
x:node.x, y:node.y+5, 'text-anchor':'middle',
'font-size':'14', 'font-family':'Georgia,serif',
'font-weight':'bold', fill:'white'
}, node.lbl));
}
// Pulse ring on highlighted
if (isHL) {
const r2 = (node.t==='int') ? (nid==='root'?33:28) : 20;
const ring = mk('circle', {
cx:node.x, cy:node.y, r:r2+7,
fill:'none', stroke:'#f4a03a', 'stroke-width':1.5,
opacity:0.55
});
svg.appendChild(ring);
}
}
}
/* ── info panel ─────────────────────────────────────────── */
function renderPanel(p) {
const div = document.getElementById('id3-panel');
if (p.t === 'ent') {
const tot = p.si + p.no;
div.innerHTML =
`<strong style="color:#1a3a5c;">${p.lbl}</strong>
<div style="display:flex;gap:20px;margin-top:6px;align-items:center;flex-wrap:wrap;">
<div>
<span style="background:#2d6a4f;color:#fff;padding:1px 9px;border-radius:3px;">Sí: ${p.si}</span>
<span style="background:#9d0208;color:#fff;padding:1px 9px;border-radius:3px;">No: ${p.no}</span>
n = ${tot}
</div>
<div style="color:#333;">
H = −<sup>${p.si}</sup>⁄<sub>${tot}</sub>·log₂(<sup>${p.si}</sup>⁄<sub>${tot}</sub>)
− <sup>${p.no}</sup>⁄<sub>${tot}</sub>·log₂(<sup>${p.no}</sup>⁄<sub>${tot}</sub>)
= <strong>${p.H.toFixed(3)}</strong>
${p.H===0 ? ' <span style="color:#2d6a4f;font-weight:bold;">← nodo puro ✓</span>' : ''}
</div>
<div style="flex:1;max-width:160px;">
<div style="height:8px;background:#e8ecf0;border-radius:4px;overflow:hidden;">
<div style="height:100%;width:${p.H*100}%;background:linear-gradient(to right,#2d6a4f,#9d0208);border-radius:4px;"></div>
</div>
<div style="font-size:0.77em;color:#999;margin-top:2px;">Impureza: ${(p.H*100).toFixed(0)}%</div>
</div>
</div>`;
}
else if (p.t === 'gains') {
const mx = Math.max(...p.gains.map(g=>g.g));
div.innerHTML =
`<strong style="color:#1a3a5c;">Gain(S, A) — ganancia de información por atributo</strong>
<table style="width:100%;margin-top:7px;border-collapse:collapse;font-size:0.85em;">
<tr style="color:#666;border-bottom:1px solid #ddd;">
<th style="text-align:left;padding:2px 8px;">Atributo</th>
<th style="text-align:left;padding:2px 8px;">Gain</th>
<th style="padding:2px 8px;min-width:110px;"></th>
<th style="padding:2px 4px;"></th>
</tr>
${p.gains.map(g => `
<tr style="border-bottom:1px solid #eef;${g.best?'background:#f0f5ff;':''}">
<td style="padding:4px 8px;font-weight:${g.best?'bold':'normal'};">${g.a}</td>
<td style="padding:4px 8px;font-weight:${g.best?'bold':'normal'};">${g.g.toFixed(3)}</td>
<td style="padding:4px 8px;">
<div style="height:7px;background:#e0e8f0;border-radius:3px;overflow:hidden;">
<div style="height:100%;width:${g.g/mx*100}%;background:${g.best?'#1a3a5c':'#7ca3c0'};border-radius:3px;"></div>
</div>
</td>
<td style="padding:4px 6px;color:#1a6f25;font-weight:bold;white-space:nowrap;">${g.best?'← elegido':''}</td>
</tr>`).join('')}
</table>`;
}
else if (p.t === 'sub') {
div.innerHTML =
`<strong style="color:#1a3a5c;">Subconjuntos resultantes de la división</strong>
<div style="display:flex;gap:9px;margin-top:8px;flex-wrap:wrap;">
${p.subs.map(s => `
<div style="flex:1;min-width:155px;border:1px solid ${s.pure?'#2d6a4f':'#bbc'};
border-radius:5px;padding:7px 11px;background:${s.pure?'#f0faf4':'#fafafa'};">
<div style="font-weight:bold;font-size:0.82em;color:#333;margin-bottom:4px;">${s.lbl}</div>
<div style="font-size:0.81em;margin-bottom:3px;">
<span style="background:#2d6a4f;color:#fff;padding:0 6px;border-radius:3px;">Sí: ${s.si}</span>
<span style="background:#9d0208;color:#fff;padding:0 6px;border-radius:3px;margin-left:4px;">No: ${s.no}</span>
</div>
<div style="font-size:0.81em;">H = <strong>${s.H.toFixed(3)}</strong>
${s.pure?'<span style="color:#2d6a4f;"> ← puro ✓</span>':''}
</div>
</div>`).join('')}
</div>`;
}
else if (p.t === 'rules') {
div.innerHTML =
`<strong style="color:#1a3a5c;">Reglas SI-ENTONCES extraídas del árbol</strong>
<ol style="margin:6px 0 0;padding-left:18px;line-height:2;font-size:0.82em;">
<li><code>SI Pronóstico = Nublado</code>
→ <span style="background:#2d6a4f;color:#fff;padding:0 7px;border-radius:3px;">Sí</span></li>
<li><code>SI Pronóstico = Soleado ∧ Humedad = Alta</code>
→ <span style="background:#9d0208;color:#fff;padding:0 7px;border-radius:3px;">No</span></li>
<li><code>SI Pronóstico = Soleado ∧ Humedad = Normal</code>
→ <span style="background:#2d6a4f;color:#fff;padding:0 7px;border-radius:3px;">Sí</span></li>
<li><code>SI Pronóstico = Lluvia ∧ Viento = Débil</code>
→ <span style="background:#2d6a4f;color:#fff;padding:0 7px;border-radius:3px;">Sí</span></li>
<li><code>SI Pronóstico = Lluvia ∧ Viento = Fuerte</code>
→ <span style="background:#9d0208;color:#fff;padding:0 7px;border-radius:3px;">No</span></li>
</ol>
<div style="margin-top:5px;font-size:0.78em;color:#888;">
Precisión en entrenamiento: 15/15 = 100 % · Temperatura no fue seleccionada en ningún nodo
</div>`;
}
}
/* ── controller ─────────────────────────────────────────── */
let cur = 0;
function render() {
const s = STEPS[cur];
document.getElementById('id3-badge').textContent = s.badge;
document.getElementById('id3-desc').textContent = s.desc;
document.getElementById('id3-ctr').textContent = `${cur+1} / ${STEPS.length}`;
document.getElementById('id3-prev').disabled = (cur === 0);
document.getElementById('id3-next').disabled = (cur === STEPS.length-1);
drawTree(s);
renderPanel(s.panel);
}
window.id3Nav = function(d) {
cur = Math.max(0, Math.min(STEPS.length-1, cur+d));
render();
};
render();
})();
</script>
```
## Extracción de reglas de clasificación
Una de las ventajas principales de los árboles de decisión es que pueden transformarse en reglas de clasificación. Cada camino desde la raíz hasta una hoja produce una regla de tipo SI-ENTONCES.
Del árbol anterior se obtienen las siguientes reglas:
1. SI `Pronóstico = Soleado` Y `Humedad = Alta`, ENTONCES `Juega = No`.
2. SI `Pronóstico = Soleado` Y `Humedad = Normal`, ENTONCES `Juega = Sí`.
3. SI `Pronóstico = Nublado`, ENTONCES `Juega = Sí`.
4. SI `Pronóstico = Lluvia` Y `Viento = Débil`, ENTONCES `Juega = Sí`.
5. SI `Pronóstico = Lluvia` Y `Viento = Fuerte`, ENTONCES `Juega = No`.
::: {.callout-note appearance=“minimal”}
Definición. Una regla de clasificación extraída de un árbol es una implicación lógica formada por las condiciones de un camino desde la raíz hasta una hoja:
$$
\text{SI } (A_1=v_1) \land (A_2=v_2) \land \cdots \land (A_k=v_k) \text{ ENTONCES } y=c.
$$ {#eq-classification-rule}
:::
Estas reglas son interpretables y pueden comunicarse fácilmente a personas no especialistas. Por esta razón, los árboles de decisión se han utilizado en aplicaciones como diagnóstico médico, evaluación de riesgo crediticio, mantenimiento predictivo y clasificación de clientes [@breiman1984classification; @james2021introduction].
## Implementación con `scikit-learn`
Aunque el ejemplo anterior calcula manualmente la entropía y la ganancia de información, en la práctica se usan bibliotecas especializadas. En Python, `scikit-learn` proporciona implementaciones eficientes de árboles de decisión [@scikit-learn].
Para trabajar con variables categóricas, primero se codifican mediante variables indicadoras. Después se ajusta un árbol usando el criterio `entropy`, que corresponde a la ganancia de información.
```{python}
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
X = df.drop(columns="Juega")
y = df["Juega"]
categorical_features = X.columns.tolist()
preprocess = ColumnTransformer(
transformers=[
("cat", OneHotEncoder(handle_unknown="ignore"), categorical_features)
]
)
model = DecisionTreeClassifier(
criterion="entropy",
max_depth=3,
random_state=42
)
clf = Pipeline(steps=[
("preprocess", preprocess),
("model", model)
])
clf.fit(X, y)
clf.predict(X)
```
En conjuntos pequeños, evaluar sobre los mismos datos de entrenamiento solo sirve como verificación técnica. En problemas reales, debe separarse un conjunto de prueba o usarse validación cruzada.
```{python}
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.30,
random_state=42,
stratify=y
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
```
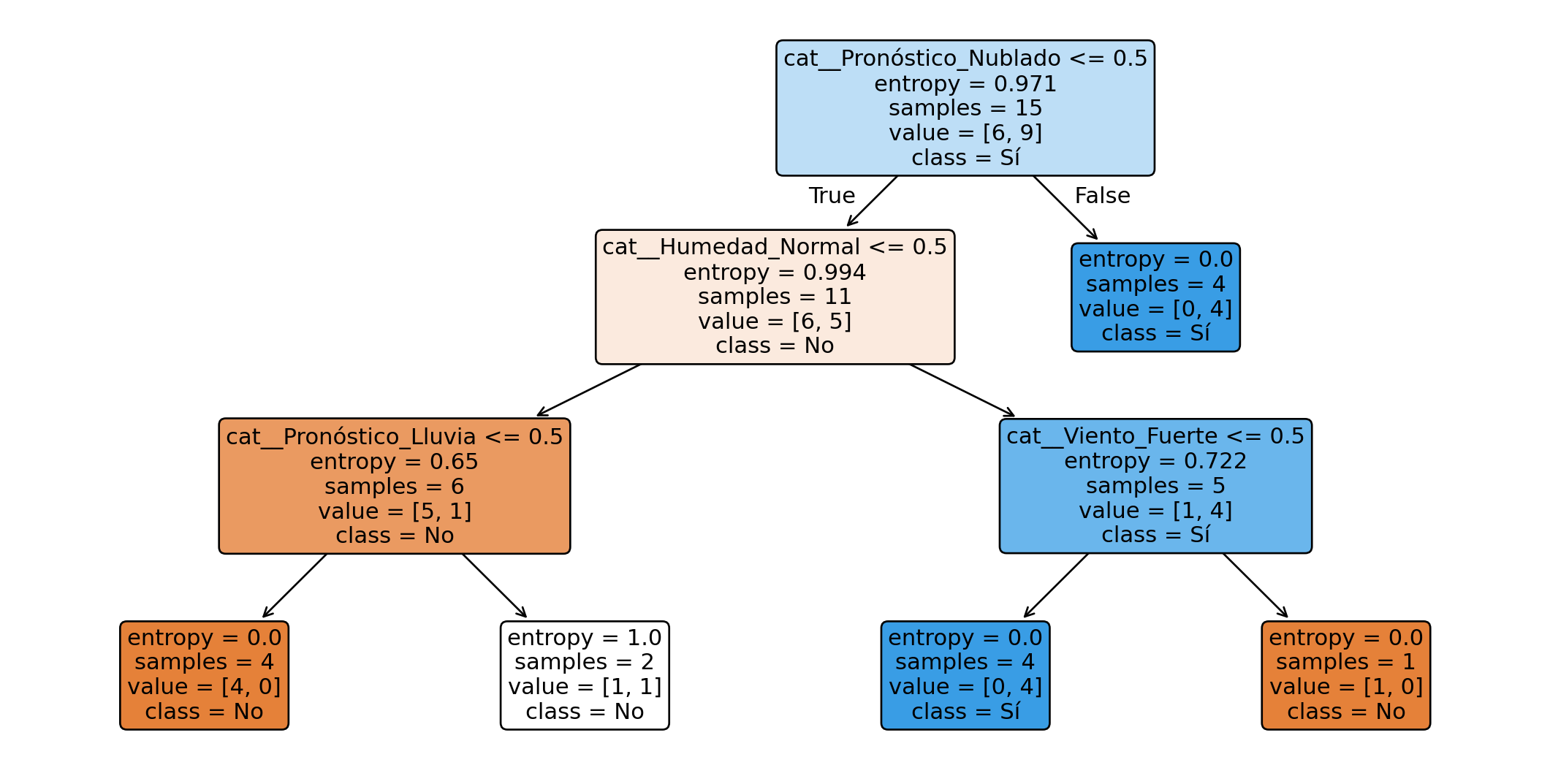
## Visualización del árbol
```{python}
import matplotlib.pyplot as plt
clf.fit(X, y)
feature_names = clf.named_steps["preprocess"].get_feature_names_out()
tree_model = clf.named_steps["model"]
plt.figure(figsize=(14, 7))
plot_tree(
tree_model,
feature_names=feature_names,
class_names=tree_model.classes_,
filled=True,
rounded=True
)
plt.show()
```
La visualización permite inspeccionar qué variables fueron utilizadas y cómo se organizaron las divisiones. En árboles más grandes, la visualización puede volverse difícil de leer; por ello se recomienda controlar hiperparámetros como `max_depth`, `min_samples_split` y `min_samples_leaf`.
## Complejidad computacional
La complejidad de construir un árbol depende del número de ejemplos $n$, el número de atributos $m$, el número de clases y el costo de evaluar divisiones. Para atributos categóricos, una estimación simplificada del costo en cada nodo consiste en revisar los atributos disponibles y calcular la distribución de clases por valor del atributo. Si se hace de forma directa, el costo puede aproximarse por $O(mn)$ en la raíz.
A lo largo del árbol, el costo total depende de cómo se reparten los datos entre nodos. En árboles balanceados, cada nivel procesa en conjunto aproximadamente $n$ ejemplos, por lo que una estimación razonable es
$$
O(mn d),
$$
donde $d$ es la profundidad del árbol. En el peor caso, la profundidad puede crecer hasta $n$, produciendo costos mayores y árboles poco generalizables. Para variables continuas, además puede ser necesario ordenar valores o evaluar umbrales candidatos, lo que modifica el costo de entrenamiento [@hastie2009elements; @scikit-learn].
::: {.callout-note appearance=“minimal”}
Definición. Si $n$ es el número de ejemplos, $m$ el número de atributos y $d$ la profundidad del árbol, una estimación simplificada del costo de inducción de un árbol categórico es:
$$
T(n,m,d) = O(mnd).
$$ {#eq-tree-complexity}
:::
La predicción con un árbol ya entrenado suele ser eficiente. Para clasificar una observación, basta recorrer un camino desde la raíz hasta una hoja, por lo que el costo de inferencia es $O(d)$.
## Ventajas y limitaciones
Los árboles de decisión presentan varias ventajas:
- son fáciles de explicar;
- generan reglas interpretables;
- permiten combinar variables categóricas y numéricas;
- requieren relativamente poca preparación de escalas;
- pueden capturar interacciones no lineales entre variables.
Sin embargo, también tienen limitaciones importantes:
- pueden sobreajustarse si crecen sin restricciones;
- son sensibles a pequeñas variaciones en los datos;
- ID3 favorece atributos con muchos valores posibles;
- la versión clásica de ID3 no maneja directamente variables continuas;
- una decisión local óptima no garantiza un árbol globalmente óptimo.
La naturaleza *greedy* de ID3 implica que el algoritmo elige el mejor atributo en cada nodo según una medida local. Esto hace que el procedimiento sea eficiente, pero no garantiza encontrar el árbol óptimo global. En la práctica, técnicas como poda, validación cruzada y métodos de ensamble ayudan a mejorar la generalización [@breiman1984classification; @hastie2009elements].
## Conclusiones
La clasificación supervisada busca asignar etiquetas categóricas a nuevas observaciones usando información aprendida a partir de ejemplos históricos. Los árboles de decisión ofrecen una forma clara e interpretable de resolver esta tarea mediante una secuencia de preguntas sobre los atributos.
El algoritmo de Hunt proporciona la estructura recursiva general para construir árboles. ID3 especifica un criterio para elegir atributos usando entropía y ganancia de información. La entropía mide la impureza de un conjunto de ejemplos, mientras que la ganancia de información mide cuánto se reduce esa impureza después de dividir por un atributo.
El ejemplo del partido de béisbol muestra cómo se calcula la entropía inicial, cómo se comparan atributos, cómo se elige la raíz y cómo se construyen ramas sucesivas hasta obtener un árbol final. Además, el árbol puede convertirse en reglas SI-ENTONCES, lo que facilita su interpretación y comunicación.
En aplicaciones reales, los árboles de decisión deben evaluarse cuidadosamente para evitar sobreajuste. Aun así, siguen siendo una herramienta central en ciencia de datos por su equilibrio entre capacidad predictiva, simplicidad e interpretabilidad.