La evaluación de un modelo de clasificación es una etapa central del aprendizaje supervisado. En este tipo de problemas se dispone de un conjunto de observaciones para las cuales se conocen tanto las variables predictoras como la etiqueta o clase verdadera. A partir de estos datos, el objetivo es aprender una regla de decisión capaz de asignar una clase a nuevas observaciones no vistas durante el entrenamiento (hastie2009elements?; james2021introduction?).
En términos prácticos, evaluar un clasificador no significa únicamente calcular cuántas predicciones son correctas. La calidad de un modelo depende también de cómo se distribuyen sus errores, del balance entre clases, del coste relativo de falsos positivos y falsos negativos, y del contexto de uso. Por ejemplo, en un sistema de filtrado de spam puede ser aceptable que algunos correos no deseados lleguen a la bandeja principal, pero puede ser mucho más grave clasificar como spam un correo importante. En un sistema de detección médica, en cambio, puede ser preferible generar falsos positivos antes que dejar pasar casos reales de enfermedad (fawcett2006introduction?; saito2015precision?).
Este capítulo desarrolla los elementos fundamentales para evaluar modelos de clasificación. Primero se estudian los métodos de partición de datos, como holdout y validación cruzada \(K\)-fold. Después se introducen la matriz de confusión y las principales métricas derivadas de ella: exactitud, tasa de error, precisión, recall, sensibilidad, especificidad y F1-score. Finalmente, se discute la curva ROC, el área bajo la curva y la selección de métricas según la necesidad del problema.
26.2 Aprendizaje supervisado y evaluación
En aprendizaje supervisado se trabaja con un conjunto de datos etiquetado. Cada observación contiene un vector de características \(\mathbf{x}_i\) y una etiqueta asociada \(y_i\). En clasificación binaria, la etiqueta suele tomar valores en \(\{0,1\}\), donde \(1\) representa la clase positiva y \(0\) la clase negativa.
Note
Definición. Un conjunto de datos supervisado es una colección de pares entrada–salida: \[
\mathcal{D} = \{(\mathbf{x}_i, y_i)\}_{i=1}^{n},
\qquad
\mathbf{x}_i \in \mathbb{R}^p,\quad y_i \in \mathcal{Y}
\]
El modelo de clasificación puede entenderse como una función entrenable \[
f_\theta:\mathbb{R}^p \to \mathcal{Y},
\] donde \(\theta\) representa los parámetros aprendidos a partir de los datos. En modelos probabilísticos, el clasificador puede producir una puntuación o probabilidad estimada: \[
\hat{p}_i = P_\theta(y_i = 1 \mid \mathbf{x}_i).
\] Para convertir esta puntuación en una clase, se usa un umbral de decisión \(\tau\): \[
\hat{y}_i =
\begin{cases}
1, & \hat{p}_i \geq \tau,\\
0, & \hat{p}_i < \tau.
\end{cases}
\]
La evaluación se realiza sobre datos no utilizados para entrenar el modelo. Esto busca estimar su capacidad de generalización, es decir, su desempeño ante nuevas observaciones. Si se evalúa el modelo únicamente sobre los datos de entrenamiento, se corre el riesgo de obtener una estimación demasiado optimista debido al sobreajuste (hastie2009elements?; bishop2006pattern?).
26.3 Partición de datos
Una práctica estándar consiste en dividir el conjunto de datos en subconjuntos con funciones distintas. La presentación base distingue entre conjunto de entrenamiento, conjunto de validación y conjunto de prueba.
Note
Definición. Una partición entrenamiento–validación–prueba divide el conjunto de datos en tres subconjuntos disjuntos: \[
\mathcal{D} =
\mathcal{D}_{\text{train}}
\cup
\mathcal{D}_{\text{val}}
\cup
\mathcal{D}_{\text{test}},
\qquad
\mathcal{D}_{a} \cap \mathcal{D}_{b} = \varnothing
\quad (a \neq b)
\]
El conjunto de entrenamiento se usa para ajustar los parámetros del modelo. El conjunto de validación se usa para comparar configuraciones, ajustar hiperparámetros o seleccionar entre modelos candidatos. El conjunto de prueba se reserva hasta el final para estimar el desempeño del modelo seleccionado.
Una partición típica puede ser:
Subconjunto
Porcentaje típico
Función principal
Entrenamiento
70 %
Ajustar el modelo
Validación
15 %
Seleccionar hiperparámetros o modelos
Prueba
15 %
Evaluar el modelo final
Otra alternativa, frecuente cuando se desea dedicar más datos a validación y prueba, es dividir en 50 % para entrenamiento, 25 % para validación y 25 % para prueba. La elección depende del tamaño del dataset, del coste computacional y de la estabilidad esperada de la evaluación.
26.3.1 Método holdout
El método holdout, o método de reserva, consiste en dividir el conjunto de datos una sola vez. Por ejemplo, se puede asignar 80 % de las observaciones al conjunto de entrenamiento y 20 % al conjunto de prueba.
Note
Definición. En el método holdout se construye una partición única: \[
\mathcal{D} = \mathcal{D}_{\text{train}} \cup \mathcal{D}_{\text{test}},
\qquad
\mathcal{D}_{\text{train}} \cap \mathcal{D}_{\text{test}} = \varnothing
\]
Su principal ventaja es la simplicidad. Es fácil de implementar, rápido de ejecutar y escalable a conjuntos de datos grandes. Sin embargo, su principal desventaja es que la evaluación depende fuertemente de la partición realizada. Si por azar el conjunto de prueba contiene ejemplos demasiado fáciles, el rendimiento parecerá mejor de lo real. Si contiene ejemplos particularmente difíciles o atípicos, el rendimiento parecerá peor.
En problemas con clases desbalanceadas, el holdout aleatorio puede producir particiones con representación insuficiente de la clase minoritaria. Por ejemplo, si un dataset contiene 950 registros de pacientes sin enfermedad y solo 50 con enfermedad, una división aleatoria puede dejar pocos casos positivos en validación o prueba. Esto vuelve inestable la estimación de métricas como recall o sensibilidad.
26.3.2 Muestreo aleatorio estratificado
Para reducir el riesgo de particiones no representativas, se usa el muestreo estratificado. La idea es preservar aproximadamente la proporción de clases en cada subconjunto. Si la clase A representa 80 % del dataset y la clase B representa 20 %, entonces entrenamiento, validación y prueba deben conservar proporciones cercanas a 80 % y 20 %.
Note
Definición. Una partición estratificada preserva aproximadamente la distribución marginal de clases: \[
P_{\mathcal{D}_{\text{train}}}(Y=y)
\approx
P_{\mathcal{D}_{\text{val}}}(Y=y)
\approx
P_{\mathcal{D}_{\text{test}}}(Y=y)
\approx
P_{\mathcal{D}}(Y=y)
\]
La estratificación es especialmente útil cuando hay desbalance de clases. No obstante, no elimina todos los problemas. Aunque preserve proporciones, puede ocurrir que algunos subconjuntos contengan casos más fáciles, más difíciles o más atípicos que otros. En datasets pequeños, incluso la estratificación puede ser insuficiente para obtener una evaluación estable.
26.3.3 Holdout repetido
Una extensión natural del holdout es repetir varias veces el proceso de partición aleatoria y promediar las métricas. Así se reduce la dependencia respecto a una única división.
Note
Definición. En holdout repetido se generan \(R\) particiones independientes y se reporta el promedio de una métrica \(M\): \[
\bar{M}
=
\frac{1}{R}
\sum_{r=1}^{R}
M^{(r)}
\]
Por ejemplo, si cinco repeticiones producen exactitudes de 85 %, 82 %, 88 %, 84 % y 86 %, el promedio es: \[
\bar{M}
=
\frac{85 + 82 + 88 + 84 + 86}{5}
=
85\%.
\]
Este método ofrece una evaluación más estable que el holdout simple, pero tiene una limitación: algunos registros pueden aparecer muchas veces en conjuntos de prueba o entrenamiento, mientras que otros pueden aparecer pocas veces o ninguna. Por ello, cuando el tamaño del dataset es reducido, la validación cruzada suele ser una alternativa más sistemática.
26.3.4 Validación cruzada K-fold
La validación cruzada \(K\)-fold divide el conjunto de datos en \(K\) subconjuntos llamados folds. El modelo se entrena \(K\) veces. En cada iteración, un fold se usa como prueba y los \(K-1\) folds restantes se usan como entrenamiento (stone1974cross?; kohavi1995study?).
Note
Definición. En validación cruzada \(K\)-fold, una métrica \(M\) se estima como el promedio de las métricas obtenidas en los \(K\) folds: \[
\widehat{M}_{\text{CV}}
=
\frac{1}{K}
\sum_{k=1}^{K}
M_k
\]
Por ejemplo, con \(K=5\), cada fold puede contener 20 % de los datos. En la primera iteración se prueba con el fold 1 y se entrena con los folds 2, 3, 4 y 5. En la segunda iteración se prueba con el fold 2 y se entrena con los demás, y así sucesivamente.
Si las exactitudes obtenidas son 82 %, 80 %, 84 %, 81 % y 83 %, entonces: \[
\widehat{M}_{\text{CV}}
=
\frac{82 + 80 + 84 + 81 + 83}{5}
=
82\%.
\]
La validación cruzada usa mejor los datos disponibles porque cada observación se evalúa exactamente una vez y se usa para entrenamiento en \(K-1\) iteraciones. Su principal coste es computacional: el modelo debe entrenarse \(K\) veces. Por esta razón, \(K=5\) o \(K=10\) son elecciones frecuentes en la práctica (kohavi1995study?).
26.4 Ejemplo en Python: partición holdout y validación cruzada
El siguiente ejemplo usa scikit-learn para entrenar una regresión logística en un problema binario. Se muestra primero una partición holdout estratificada y después validación cruzada \(K\)-fold.
Este ejemplo también ilustra por qué no basta con observar solo accuracy. En un dataset desbalanceado, un clasificador puede obtener alta exactitud simplemente favoreciendo la clase mayoritaria, pero tener bajo recall sobre la clase positiva.
26.5 Matriz de confusión
La matriz de confusión resume la relación entre las etiquetas reales y las predicciones del modelo. En clasificación binaria se compone de cuatro cantidades: verdaderos positivos, verdaderos negativos, falsos positivos y falsos negativos.
Note
Definición. Para una clase positiva \(1\) y una clase negativa \(0\), la matriz de confusión se define por: \[
\begin{array}{c|cc}
& \hat{y}=0 & \hat{y}=1\\
\hline
y=0 & TN & FP\\
y=1 & FN & TP
\end{array}
\]
Las cantidades se interpretan así:
Cantidad
Nombre
Interpretación
\(TP\)
Verdadero positivo
El caso era positivo y el modelo predijo positivo
\(TN\)
Verdadero negativo
El caso era negativo y el modelo predijo negativo
\(FP\)
Falso positivo
El caso era negativo, pero el modelo predijo positivo
\(FN\)
Falso negativo
El caso era positivo, pero el modelo predijo negativo
En el ejemplo de detección de spam, un falso positivo ocurre cuando un correo legítimo se clasifica como spam. Un falso negativo ocurre cuando un correo spam se clasifica como no spam.
26.6 Métricas básicas de clasificación
A partir de la matriz de confusión se definen las principales métricas de evaluación. Cada una responde una pregunta distinta, por lo que ninguna métrica es universalmente superior.
26.6.1 Exactitud y tasa de error
Note
Definición. La exactitud o accuracy es la proporción total de predicciones correctas: \[
\text{Accuracy}
=
\frac{TP + TN}{TP + TN + FP + FN}
\]
La accuracy responde: ¿qué porcentaje total de observaciones clasificó correctamente el modelo? Es útil cuando las clases están relativamente balanceadas y cuando los costes de los errores son similares.
Note
Definición. La tasa de error es la proporción total de predicciones incorrectas: \[
\text{Error Rate}
=
\frac{FP + FN}{TP + TN + FP + FN}
=
1 - \text{Accuracy}
\]
La tasa de error responde: ¿qué porcentaje de decisiones fueron incorrectas?
26.6.2 Precisión
Note
Definición. La precisión mide qué proporción de las predicciones positivas fueron correctas: \[
\text{Precision}
=
\frac{TP}{TP + FP}
\]
La precisión responde: cuando el modelo predice positivo, ¿qué tan seguido tiene razón? Es una métrica importante cuando los falsos positivos son costosos. Por ejemplo, en un sistema que marca transacciones como fraudulentas, una baja precisión puede generar demasiadas falsas alarmas.
26.6.3 Recall, sensibilidad y tasa de verdaderos positivos
Note
Definición. El recall o sensibilidad mide qué proporción de positivos reales fueron detectados: \[
\text{Recall}
=
\text{Sensitivity}
=
\text{TPR}
=
\frac{TP}{TP + FN}
\]
El recall responde: de todos los casos positivos reales, ¿cuántos encontró el modelo? Es fundamental cuando los falsos negativos son costosos. En screening médico, por ejemplo, suele priorizarse una alta sensibilidad para reducir el riesgo de dejar pasar casos reales.
26.6.4 Especificidad y tasa de falsos positivos
Note
Definición. La especificidad mide qué proporción de negativos reales fueron identificados correctamente: \[
\text{Specificity}
=
\frac{TN}{TN + FP}
\]
La especificidad responde: de todos los casos negativos reales, ¿cuántos fueron clasificados correctamente como negativos? Es importante cuando se desea evitar falsas alarmas.
Note
Definición. La tasa de falsos positivos mide qué proporción de negativos reales fueron clasificados erróneamente como positivos: \[
\text{FPR}
=
\frac{FP}{FP + TN}
=
1 - \text{Specificity}
\]
La tasa de falsos positivos es central para construir la curva ROC.
26.6.5 F1-score
Note
Definición. El F1-score es la media armónica entre precisión y recall: \[
F_1
=
2
\cdot
\frac{\text{Precision}\cdot \text{Recall}}
{\text{Precision} + \text{Recall}}
\]
El F1-score es útil cuando se desea balancear precisión y recall en una sola medida. Al ser una media armónica, penaliza valores muy bajos de cualquiera de las dos métricas. Por ello resulta especialmente informativo en problemas con clases desbalanceadas (sokolova2009systematic?).
26.6.6 Exactitud balanceada
Note
Definición. La exactitud balanceada es el promedio entre sensibilidad y especificidad: \[
\text{Balanced Accuracy}
=
\frac{\text{Sensitivity} + \text{Specificity}}{2}
\]
Esta métrica es útil cuando las clases están desbalanceadas, porque no permite que el desempeño sobre la clase mayoritaria domine completamente la evaluación.
26.7 Ejemplo en Python: matriz de confusión y métricas
from sklearn.metrics import confusion_matrix, classification_reportcm = confusion_matrix(y_test, y_pred)cm
¿Hay compromiso entre falsos positivos y falsos negativos?
Un ejemplo clásico es la detección de cáncer en pruebas de screening. Supongamos dos modelos:
Modelo
TPR
FPR
A
0.92
0.35
B
0.81
0.08
El modelo A detecta más casos positivos reales, pero también genera más falsos positivos. En screening médico, la alta sensibilidad puede ser preferible porque es muy importante no dejar pasar casos reales. Sin embargo, si los falsos positivos generan pruebas invasivas, ansiedad o costes elevados, el modelo B podría ser más equilibrado. Esta decisión no puede tomarse solo con una métrica; requiere entender el coste de cada error y el uso final del sistema (fawcett2006introduction?).
26.9 Umbral de decisión
Muchos clasificadores producen puntuaciones continuas o probabilidades estimadas. La clase final depende del umbral \(\tau\). Cambiar el umbral modifica la matriz de confusión y, por tanto, todas las métricas.
Note
Definición. Dada una puntuación \(\hat{p}(\mathbf{x})\), una regla de clasificación binaria con umbral \(\tau\) se define como: \[
\hat{y}(\mathbf{x};\tau)
=
\mathbb{I}\{\hat{p}(\mathbf{x}) \geq \tau\}
\]
Si se baja el umbral de decisión de 0.70 a 0.30, más observaciones serán clasificadas como positivas. En general, esto aumenta el TPR porque se detectan más positivos reales, pero también aumenta el FPR porque más negativos son clasificados erróneamente como positivos.
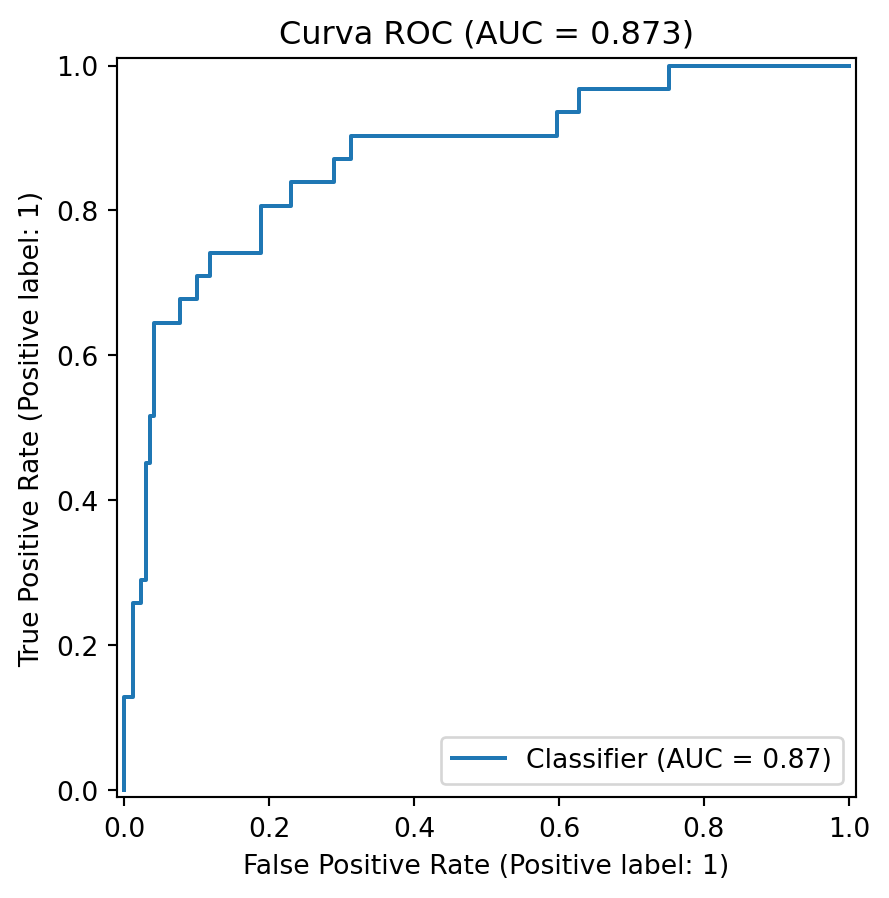
La curva ROC permite analizar el rendimiento del clasificador para todos los posibles umbrales de decisión. En el eje vertical se grafica la tasa de verdaderos positivos, y en el eje horizontal la tasa de falsos positivos (fawcett2006introduction?).
Note
Definición. La curva ROC es el conjunto de puntos: \[
\text{ROC}
=
\left\{
\left(
\text{FPR}(\tau),
\text{TPR}(\tau)
\right)
:
\tau \in \mathbb{R}
\right\}
\]
Un clasificador ideal se acerca a la esquina superior izquierda, donde \(\text{TPR}=1\) y \(\text{FPR}=0\). La línea diagonal representa un clasificador sin valor predictivo. Un modelo cuya curva está cerca de esa diagonal no discrimina bien entre positivos y negativos.
El AUC resume el área bajo la curva ROC. Puede interpretarse como la probabilidad de que el modelo asigne una puntuación mayor a una observación positiva elegida al azar que a una observación negativa elegida al azar (fawcett2006introduction?).
Note
Definición. El área bajo la curva ROC se define como: \[
\text{AUC}
=
\int_{0}^{1}
\text{TPR}(\text{FPR})\,d(\text{FPR})
\]
Una interpretación usual de AUC es:
AUC
Interpretación general
0.90–1.00
Sobresaliente
0.80–0.90
Bueno o excelente
0.70–0.80
Aceptable
0.60–0.70
Bajo
0.50–0.60
Sin buena discriminación
Estas categorías deben usarse con cuidado. Un AUC alto no garantiza que el modelo sea adecuado para todos los umbrales ni para todos los costes de error. Además, en problemas fuertemente desbalanceados, la curva Precision–Recall puede ser más informativa que la curva ROC (saito2015precision?).
Si un clasificador tiene \(\text{AUC}=0.50\), significa que no discrimina mejor que el azar. En un ejemplo médico, si se compara al azar un paciente con cáncer y uno sin cáncer, el modelo solo tendría 50 % de probabilidad de asignar una puntuación mayor al paciente con cáncer.
La curva ROC no fija un único umbral. En su lugar, muestra el comportamiento del modelo al variar el umbral. Esto permite elegir un punto de operación de acuerdo con las necesidades del problema.
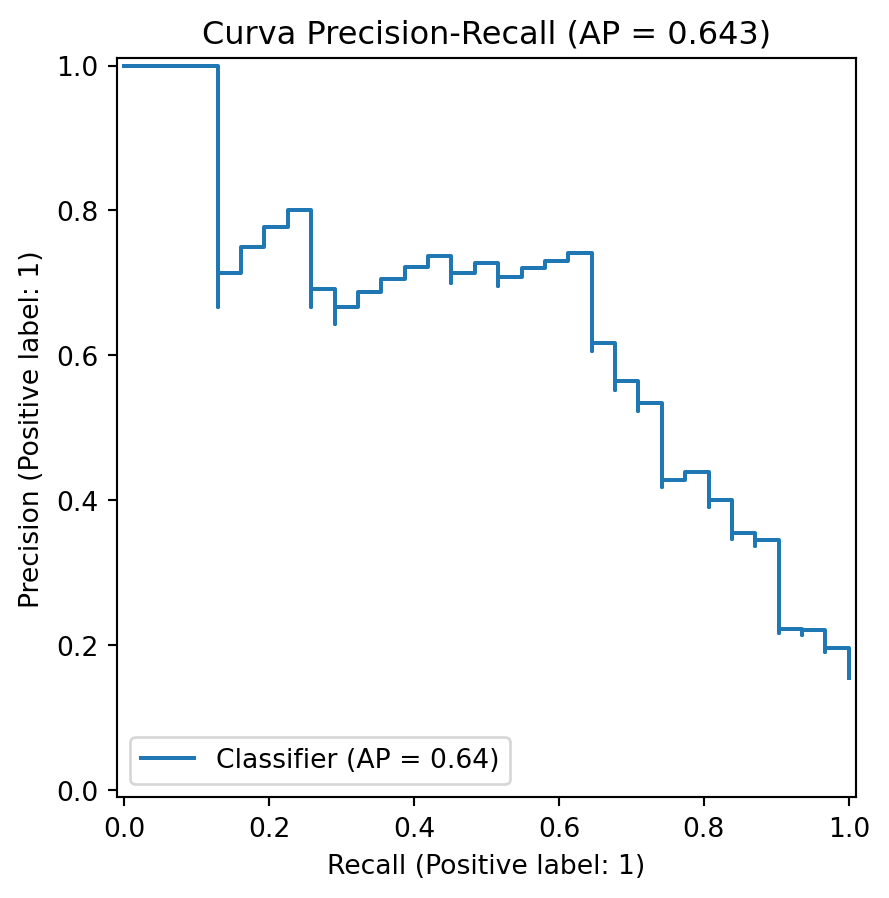
26.12 Comparación con la curva Precision–Recall
Aunque la presentación se centra en ROC y AUC, es importante mencionar una limitación: cuando la clase positiva es rara, la curva ROC puede presentar una visión demasiado optimista del desempeño. En estos casos, la curva Precision–Recall suele ser más sensible a los cambios en la detección de la clase minoritaria (saito2015precision?).
Note
Definición. La curva Precision–Recall representa el conjunto de puntos: \[
\text{PR}
=
\left\{
\left(
\text{Recall}(\tau),
\text{Precision}(\tau)
\right)
:
\tau \in \mathbb{R}
\right\}
\]
from sklearn.metrics import PrecisionRecallDisplay, average_precision_scoreap = average_precision_score(y_test, probs)PrecisionRecallDisplay.from_predictions(y_test, probs)plt.title(f"Curva Precision-Recall (AP = {ap:.3f})")plt.show()
La métrica Average Precision resume el rendimiento bajo la curva Precision–Recall. A diferencia de ROC-AUC, su línea base depende de la prevalencia de la clase positiva. Si solo 15 % de las observaciones son positivas, una curva PR debe compararse contra esa prevalencia como referencia.
26.13 Flujo recomendado para evaluar clasificadores
Una evaluación reproducible puede organizarse como un flujo de trabajo:
Definir la clase positiva y el objetivo del modelo.
Separar datos de prueba antes de ajustar hiperparámetros.
Usar partición estratificada cuando haya desbalance.
Entrenar modelos candidatos en entrenamiento.
Seleccionar hiperparámetros con validación o validación cruzada.
Evaluar una sola vez el modelo final sobre prueba.
Reportar matriz de confusión y métricas alineadas con el problema.
Analizar umbrales si el modelo produce probabilidades o puntuaciones.
Documentar semillas, particiones, versiones de librerías y criterios de selección.
En proyectos reales, esta documentación es tan importante como el valor de las métricas. Sin ella, los resultados son difíciles de reproducir y comparar.
26.14 Ejemplo final: evaluación completa en Python
Este patrón permite comparar explícitamente cómo cambian las métricas al modificar el umbral. También obliga a distinguir entre evaluación basada en clases predichas y evaluación basada en puntuaciones.
26.15 Conclusiones
Evaluar un modelo de clasificación requiere más que calcular accuracy. La primera decisión importante es cómo separar los datos para estimar la generalización. El holdout es simple y rápido, pero puede ser inestable si la partición no representa adecuadamente la distribución de los datos. La validación cruzada \(K\)-fold ofrece una estimación más robusta, especialmente en conjuntos pequeños, aunque incrementa el coste computacional.
La matriz de confusión proporciona la base para entender los errores del clasificador. A partir de ella se derivan métricas como precisión, recall, especificidad, F1-score y exactitud balanceada. Cada métrica responde una pregunta diferente y debe elegirse según el objetivo del problema. En escenarios donde los falsos negativos son graves, como screening médico, puede priorizarse la sensibilidad. En escenarios donde los falsos positivos son costosos, puede priorizarse la precisión o la especificidad.
Finalmente, la curva ROC y el AUC permiten analizar el desempeño del modelo a través de distintos umbrales. Sin embargo, el umbral final debe seleccionarse con base en el coste de los errores y el contexto de aplicación. Una evaluación rigurosa no solo reporta métricas, sino que documenta cómo se obtuvieron, con qué particiones, bajo qué supuestos y con qué criterios de decisión.