---
title: "Arboles CART: árboles de clasificación y regresión"
author: "Diego Villalba"
date: today
lang: es
format:
html:
toc: true
toc-depth: 3
toc-title: "Contenido"
number-sections: true
code-fold: true
code-tools: true
code-summary: "Mostrar código"
fig-align: center
theme: cosmo
highlight-style: github
smooth-scroll: true
pdf:
toc: true
toc-depth: 3
number-sections: true
documentclass: scrbook
papersize: letter
fontsize: 11pt
geometry: margin=2.5cm
keep-tex: false
execute:
echo: true
warning: false
message: false
cache: false
bibliography: referencias_cart.bib
crossref:
fig-title: "Figura"
tbl-title: "Tabla"
eq-prefix: "Ec."
---
## Introducción
Los árboles de decisión constituyen una familia de modelos supervisados cuyo objetivo es aprender reglas de decisión a partir de datos etiquetados. En clasificación, estas reglas asignan una observación a una categoría; en regresión, estiman un valor numérico. Dentro de esta familia, el método CART (*Classification and Regression Trees*) ocupa un lugar central porque formaliza la construcción de árboles binarios capaces de tratar variables categóricas y numéricas, además de incorporar mecanismos de poda para controlar la complejidad del modelo [@breiman1984cart; @hastie2009elements].
A diferencia de algoritmos como ID3, que originalmente se formuló para árboles de clasificación con divisiones multi-rama y variables categóricas, CART construye árboles estrictamente binarios. En cada nodo, el algoritmo busca una pregunta de la forma “¿se cumple cierta condición?” y divide los datos en dos subconjuntos: los que satisfacen la condición y los que no. La idea fundamental es que cada partición produzca nodos cada vez más homogéneos respecto a la variable objetivo.
En un problema de clasificación, la homogeneidad de un nodo se mide mediante una función de impureza. CART suele utilizar el índice de Gini, aunque también pueden emplearse otras medidas. En regresión, el criterio más común se basa en la reducción de la varianza o del error cuadrático medio. Este capítulo se enfoca principalmente en CART para clasificación, siguiendo el desarrollo conceptual de árboles binarios, índice de Gini, particiones para variables categóricas y continuas, reducción de impureza, poda y complejidad computacional.
## De los árboles de decisión a CART
Un árbol de decisión representa un conjunto de reglas jerárquicas. Cada nodo interno contiene una condición sobre una variable predictora, cada rama representa el resultado de dicha condición y cada hoja contiene una predicción. Para clasificar una nueva observación, se recorre el árbol desde la raíz hasta una hoja aplicando sucesivamente las reglas aprendidas.
CART fue propuesto por Breiman, Friedman, Olshen y Stone en 1984 como un marco general para construir árboles de clasificación y regresión [@breiman1984cart]. Sus rasgos principales son los siguientes:
- construye árboles binarios;
- evalúa particiones candidatas mediante criterios de impureza;
- puede trabajar con variables numéricas y categóricas;
- selecciona localmente la mejor partición en cada nodo;
- utiliza poda de costo-complejidad para evitar árboles excesivamente grandes;
- produce modelos interpretables mediante reglas SI-ENTONCES.
::: {.callout-note appearance=“minimal”}
Definición. . Un árbol CART es un árbol de decisión binario en el que cada nodo interno $t$ particiona el subconjunto de datos $D_t$ en dos subconjuntos disjuntos $D_L$ y $D_R$ mediante una regla de decisión $s$:
$$
D_t = D_L \cup D_R, \qquad D_L \cap D_R = \varnothing.
$$
:::
La propiedad binaria es esencial: aunque una variable categórica tenga más de dos valores posibles, CART no genera una rama por categoría. En su lugar, agrupa los valores en dos bloques y evalúa qué agrupación produce la mayor mejora en pureza.
## Clasificación, pureza e impureza
En clasificación supervisada se parte de un conjunto de entrenamiento
$$
D = \{(\mathbf{x}_i, y_i)\}_{i=1}^{n},
$$
donde $\mathbf{x}_i \in \mathcal{X}$ representa las variables predictoras de la observación $i$ y $y_i \in \{1,2,\dots,K\}$ es su clase. El objetivo es aprender una función $f: \mathcal{X} \to \{1,2,\dots,K\}$ que prediga la clase de nuevas observaciones.
Un nodo es puro si todas las observaciones que contiene pertenecen a la misma clase. En ese caso, la predicción de la hoja es inequívoca. En cambio, si dentro de un nodo conviven observaciones de distintas clases, el nodo es impuro y conviene seguir dividiéndolo si existen particiones útiles.
::: {.callout-note appearance=“minimal”}
Definición. . Sea $D_t$ el conjunto de observaciones que llegan al nodo $t$. La proporción de observaciones de clase $k$ en el nodo se define como:
$$
p_{k,t} = \frac{1}{|D_t|}\sum_{(\mathbf{x}_i,y_i)\in D_t}\mathbf{1}(y_i=k).
$$
:::
Si $p_{k,t}=1$ para alguna clase $k$, entonces el nodo es puro. Si las proporciones están más repartidas entre clases, el nodo presenta mayor impureza. Esta intuición se formaliza mediante el índice de Gini.
## Índice de Gini
El índice de Gini mide la impureza de un nodo en términos de la distribución de clases. Para $K$ clases, se define como:
::: {.callout-note appearance=“minimal”}
Definición. . El índice de Gini de un nodo $D_t$ con proporciones de clase $p_{1,t},\dots,p_{K,t}$ es:
$$
Gini(D_t)=1-\sum_{k=1}^{K}p_{k,t}^{2}.
$$ {#eq-gini}
:::
Esta expresión puede interpretarse como la probabilidad de clasificar incorrectamente una observación si se asignara aleatoriamente una clase de acuerdo con la distribución empírica del nodo [@breiman1984cart; @james2021islr].
En clasificación binaria, con clases “sí” y “no”, si $p$ es la proporción de la clase positiva, entonces
$$
Gini(D_t)=1-p^2-(1-p)^2=2p(1-p).
$$
El mínimo valor es $0$, alcanzado cuando $p=0$ o $p=1$, es decir, cuando el nodo contiene una sola clase. El máximo valor en el caso binario es $0.5$, alcanzado cuando $p=0.5$.
```{python}
import numpy as np
import pandas as pd
def gini_from_counts(counts):
counts = np.asarray(counts, dtype=float)
probs = counts / counts.sum()
return 1 - np.sum(probs**2)
# Ejemplo: 9 registros de clase sí y 5 de clase no
gini_raiz = gini_from_counts([9, 5])
print(f"Gini raíz = {gini_raiz:.3f}")
```
En este ejemplo, la impureza inicial es aproximadamente $0.459$, lo cual indica que el nodo raíz todavía mezcla observaciones de ambas clases.
## Evaluación de una partición binaria
En CART, una partición divide el conjunto $D_t$ en dos subconjuntos hijos: $D_L$ y $D_R$. La calidad de la partición no se mide solo por la pureza individual de cada subconjunto, sino por una suma ponderada de sus impurezas. Esto evita favorecer divisiones que produzcan un nodo pequeño y puro pero de escasa relevancia global.
::: {.callout-note appearance=“minimal”}
Definición. . La impureza ponderada de una partición binaria $s$ que divide $D_t$ en $D_L$ y $D_R$ es:
$$
Gini_s(D_t)=\frac{|D_L|}{|D_t|}Gini(D_L)+\frac{|D_R|}{|D_t|}Gini(D_R).
$$ {#eq-weighted-gini}
:::
CART selecciona, entre las particiones candidatas, aquella que minimiza la impureza ponderada. Equivalentemente, puede seleccionarse la partición que maximiza la reducción de impureza.
::: {.callout-note appearance=“minimal”}
Definición. . La reducción de impureza producida por una partición $s$ en el nodo $D_t$ es:
$$
\Delta Gini(s,D_t)=Gini(D_t)-Gini_s(D_t).
$$ {#eq-gini-reduction}
:::
Ambas formulaciones son equivalentes para comparar particiones dentro del mismo nodo: minimizar $Gini_s(D_t)$ es lo mismo que maximizar $\Delta Gini(s,D_t)$, ya que $Gini(D_t)$ permanece constante durante la comparación.
## Particiones binarias con variables categóricas
Supongamos que una variable categórica $A$ toma valores en un conjunto finito
$$
\mathcal{A}=\{a_1,a_2,\dots,a_m\}.
$$
En lugar de crear una rama para cada valor, CART construye preguntas binarias del tipo:
$$
A \in S_A,
$$
donde $S_A$ es un subconjunto propio y no vacío de $\mathcal{A}$. Por ejemplo, si
$$
ingreso \in \{bajo, medio, alto\},
$$
entonces algunas preguntas candidatas son:
$$
ingreso \in \{bajo\}, \qquad ingreso \in \{medio\}, \qquad ingreso \in \{bajo, medio\}.
$$
Cada pregunta separa los datos en dos subconjuntos: los que cumplen la condición y los que no.
::: {.callout-note appearance=“minimal”}
Definición. . Si un atributo categórico $A$ tiene $m$ valores distintos, el número de particiones binarias no triviales distintas es:
$$
\frac{2^m-2}{2}=2^{m-1}-1.
$$ {#eq-categorical-splits}
:::
Se restan dos subconjuntos porque el subconjunto vacío y el conjunto completo no producen una partición válida. Después se divide entre dos porque $S_A$ y su complemento generan la misma partición, solo intercambiando los lados izquierdo y derecho.
```{python}
from itertools import combinations
def binary_partitions(values):
values = tuple(values)
m = len(values)
partitions = []
# Basta explorar subconjuntos hasta tamaño m-1; luego eliminamos duplicados por complemento.
seen = set()
full = frozenset(values)
for r in range(1, m):
for comb in combinations(values, r):
left = frozenset(comb)
right = full - left
key = frozenset([left, right])
if key not in seen:
seen.add(key)
partitions.append((set(left), set(right)))
return partitions
for left, right in binary_partitions(["bajo", "medio", "alto"]):
print(left, "vs", right)
```
## Particiones binarias con variables continuas
Para variables numéricas, CART busca puntos de corte. Si $A$ es una variable continua, una partición típica tiene la forma
$$
A < c \quad \text{frente a} \quad A \geq c.
$$
El procedimiento usual consiste en ordenar los valores observados de $A$, calcular puntos medios entre valores consecutivos y evaluar cada punto como candidato de corte. Esta estrategia permite convertir una variable continua en una pregunta binaria interpretable.
::: {.callout-note appearance=“minimal”}
Definición. . Dados los valores ordenados $a_{(1)}<a_{(2)}<\cdots<a_{(r)}$ de una variable numérica $A$, los puntos de corte candidatos se definen como:
$$
c_j=\frac{a_{(j)}+a_{(j+1)}}{2}, \qquad j=1,\dots,r-1.
$$ {#eq-cutpoints}
:::
Consideremos el ejemplo:
$$
(20,\text{Sí}),\quad (25,\text{Sí}),\quad (30,\text{No}),\quad (40,\text{No}).
$$
Los valores ordenados son $20,25,30,40$, por lo que los puntos medios candidatos son:
$$
22.5, \qquad 27.5, \qquad 35.
$$
Para cada corte $c$, se forman los subconjuntos
$$
D_L=\{A<c\}, \qquad D_R=\{A\geq c\},
$$
y se calcula el índice de Gini ponderado.
```{python}
import pandas as pd
edad = pd.DataFrame({
"edad": [20, 25, 30, 40],
"clase": ["Sí", "Sí", "No", "No"]
})
def gini(labels):
counts = pd.Series(labels).value_counts().to_numpy()
return gini_from_counts(counts)
def weighted_gini_for_cut(df, feature, target, c):
left = df[df[feature] < c]
right = df[df[feature] >= c]
n = len(df)
return (len(left)/n)*gini(left[target]) + (len(right)/n)*gini(right[target])
values = sorted(edad["edad"].unique())
cuts = [(values[i] + values[i+1]) / 2 for i in range(len(values)-1)]
resultados = pd.DataFrame({
"corte": cuts,
"gini_ponderado": [weighted_gini_for_cut(edad, "edad", "clase", c) for c in cuts]
})
resultados
```
El mejor corte es $c=27.5$, porque separa perfectamente las clases: a la izquierda quedan los dos casos “Sí” y a la derecha los dos casos “No”. Por tanto, el índice de Gini ponderado es $0$.
## Ejemplo completo: compra de computadora portátil
Consideremos un conjunto de datos en el que se desea predecir si una persona compra o no una computadora portátil. Las variables predictoras son edad, ingreso, si es estudiante y calificación crediticia. La variable objetivo es `compra_lap`.
```{python}
datos = pd.DataFrame({
"id": range(1, 15),
"edad": ["joven", "joven", "adulto", "a_mayor", "a_mayor", "a_mayor", "adulto", "joven", "joven", "a_mayor", "joven", "adulto", "adulto", "a_mayor"],
"ingreso": ["alto", "alto", "alto", "medio", "bajo", "bajo", "bajo", "medio", "bajo", "medio", "medio", "medio", "alto", "medio"],
"estudiante": ["no", "no", "no", "no", "si", "si", "si", "no", "si", "si", "si", "no", "si", "no"],
"calif_credito": ["favorable", "excelente", "favorable", "favorable", "favorable", "excelente", "excelente", "favorable", "favorable", "favorable", "excelente", "excelente", "favorable", "excelente"],
"compra_lap": ["no", "no", "si", "si", "si", "no", "si", "no", "si", "si", "si", "si", "si", "no"]
})
datos
```
La distribución de la variable objetivo contiene 9 casos “sí” y 5 casos “no”, por lo que la impureza del nodo raíz es:
```{python}
gini_inicial = gini(datos["compra_lap"])
print(f"Gini inicial = {gini_inicial:.3f}")
```
Para evaluar una variable categórica, se consideran todas sus particiones binarias no equivalentes. La siguiente función calcula la mejor partición de una variable categórica usando el índice de Gini ponderado.
```{python}
def weighted_gini_categorical(df, feature, target, left_values):
left_values = set(left_values)
left = df[df[feature].isin(left_values)]
right = df[~df[feature].isin(left_values)]
n = len(df)
return (len(left)/n)*gini(left[target]) + (len(right)/n)*gini(right[target])
def best_categorical_split(df, feature, target):
values = sorted(df[feature].unique())
rows = []
for left, right in binary_partitions(values):
wg = weighted_gini_categorical(df, feature, target, left)
rows.append({
"atributo": feature,
"particion_izquierda": tuple(sorted(left)),
"particion_derecha": tuple(sorted(right)),
"gini_ponderado": wg,
"reduccion": gini(df[target]) - wg
})
return pd.DataFrame(rows).sort_values("gini_ponderado")
resumen = pd.concat([
best_categorical_split(datos, col, "compra_lap").head(1)
for col in ["edad", "ingreso", "estudiante", "calif_credito"]
], ignore_index=True)
resumen.sort_values("gini_ponderado")
```
En este ejemplo, una de las mejores particiones iniciales corresponde a separar la categoría `adulto` del resto en la variable `edad`. Esta partición produce una reducción importante de impureza porque todos los registros con edad `adulto` tienen clase “sí”. Sin embargo, CART continúa evaluando particiones en los nodos hijos para construir reglas más específicas.
## Reducción de impureza e interpretación
La reducción de impureza permite comparar cuánto mejora una partición respecto al nodo original. En el ejemplo anterior, si el nodo raíz tiene
$$
Gini(D)=0.459,
$$
y una partición produce
$$
Gini_s(D)=0.357,
$$
entonces la reducción es
$$
\Delta Gini = 0.459-0.357=0.102.
$$
Una reducción más grande indica que la partición separó mejor las clases. En la práctica, CART evalúa todas las particiones candidatas disponibles en el nodo y selecciona aquella con mayor reducción de impureza. Este procedimiento se repite recursivamente en cada nodo hijo hasta que se satisface algún criterio de parada.
## Criterios de parada
Un árbol no puede crecer indefinidamente. En términos prácticos, la expansión se detiene cuando se cumple alguna de las siguientes condiciones:
- el nodo es puro;
- no quedan variables útiles para dividir;
- el número de observaciones en el nodo es menor que un umbral mínimo;
- la reducción de impureza es demasiado pequeña;
- se alcanza una profundidad máxima especificada;
- todos los posibles cortes producen particiones inválidas o equivalentes.
Estos criterios tienen un papel estadístico importante. Si el árbol crece demasiado, puede memorizar el conjunto de entrenamiento y perder capacidad de generalización. Si se detiene demasiado pronto, puede subajustar los datos y no capturar patrones relevantes.
## Poda de costo-complejidad
Una característica fundamental de CART es la poda de costo-complejidad. La idea consiste en permitir primero que el árbol crezca y luego simplificarlo eliminando ramas que aportan poca mejora predictiva en relación con su complejidad [@breiman1984cart].
Para un árbol $T$, se define una función objetivo que combina el error empírico con una penalización por tamaño:
::: {.callout-note appearance=“minimal”}
Definición. . El criterio de costo-complejidad para un árbol $T$ se define como:
$$
R_{\alpha}(T)=R(T)+\alpha |T|,
$$ {#eq-cost-complexity}
:::
Aquí, $R(T)$ representa el error del árbol, $|T|$ es el número de hojas y $\alpha\geq 0$ controla la penalización por complejidad. Cuando $\alpha=0$, no se penaliza el tamaño del árbol. A medida que $\alpha$ aumenta, se prefieren árboles más pequeños.
La poda permite obtener modelos más simples, interpretables y menos propensos al sobreajuste. En bibliotecas como `scikit-learn`, este procedimiento se implementa mediante el parámetro `ccp_alpha` [@scikit-learn-decision-trees].
```{python}
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
from sklearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X = datos[["edad", "ingreso", "estudiante", "calif_credito"]]
y = datos["compra_lap"]
preprocess = ColumnTransformer(
transformers=[("cat", OneHotEncoder(handle_unknown="ignore"), X.columns)]
)
modelo = Pipeline(steps=[
("preprocess", preprocess),
("tree", DecisionTreeClassifier(criterion="gini", random_state=42))
])
modelo.fit(X, y)
pred = modelo.predict(X)
print(f"Exactitud en entrenamiento = {accuracy_score(y, pred):.3f}")
```
El ejemplo anterior usa codificación *one-hot* para representar variables categóricas antes de entrenar un árbol de decisión con `scikit-learn`. Aunque la implementación interna de CART puede tratar particiones binarias de variables categóricas de distintas maneras según el software, este flujo es común en aplicaciones prácticas de ciencia de datos con Python.
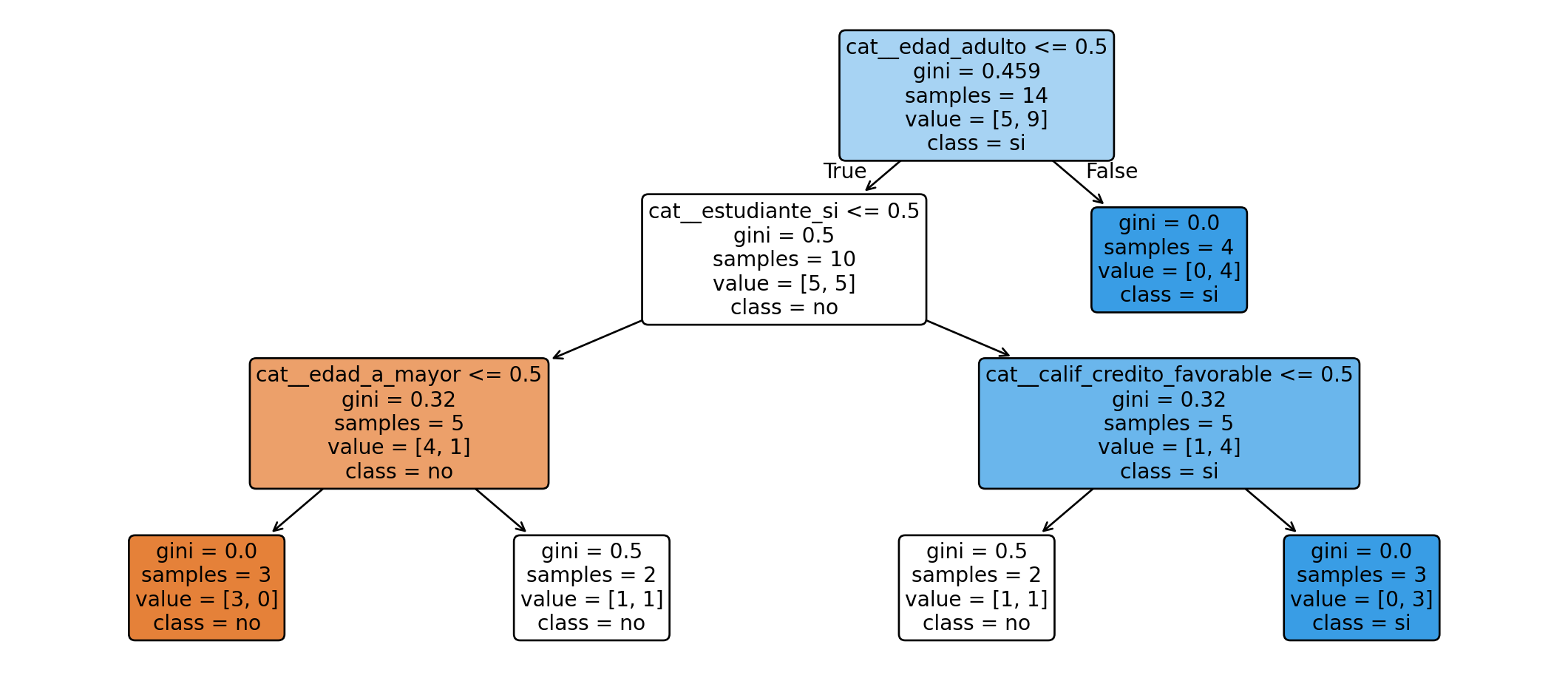
## Visualización de un árbol entrenado
```{python}
import matplotlib.pyplot as plt
modelo_simple = Pipeline(steps=[
("preprocess", preprocess),
("tree", DecisionTreeClassifier(
criterion="gini",
max_depth=3,
random_state=42
))
])
modelo_simple.fit(X, y)
feature_names = modelo_simple.named_steps["preprocess"].get_feature_names_out()
plt.figure(figsize=(14, 6))
plot_tree(
modelo_simple.named_steps["tree"],
feature_names=feature_names,
class_names=modelo_simple.named_steps["tree"].classes_,
filled=True,
rounded=True
)
plt.show()
```
La visualización permite inspeccionar las reglas aprendidas, las impurezas de cada nodo y la distribución de clases en las hojas. Esta interpretabilidad es una de las principales ventajas de los árboles de decisión frente a otros modelos más opacos.
## Extracción de reglas de clasificación
Un árbol puede traducirse a reglas SI-ENTONCES. Cada regla corresponde a un camino desde la raíz hasta una hoja. Por ejemplo, si un árbol decide primero con base en la edad y luego con base en si la persona es estudiante, una regla posible sería:
$$
\text{SI edad} \neq \text{adulto Y estudiante} = \text{sí ENTONCES compra\_lap} = \text{sí}.
$$
Esta forma de representación facilita comunicar el modelo a audiencias no técnicas. Además, permite auditar si las reglas son razonables, si dependen de variables sensibles o si reflejan sesgos presentes en los datos.
```{python}
from sklearn.tree import export_text
arbol = modelo_simple.named_steps["tree"]
reglas = export_text(arbol, feature_names=list(feature_names))
print(reglas)
```
## CART para regresión
Aunque este capítulo se ha concentrado en clasificación, CART también se utiliza para regresión. En ese caso, las hojas no predicen clases sino valores numéricos. La predicción típica de una hoja es el promedio de los valores de respuesta de las observaciones que llegan a ella.
Para elegir particiones en regresión, se busca reducir la variabilidad dentro de los nodos hijos. Un criterio común es minimizar la suma de errores cuadráticos dentro de los nodos:
::: {.callout-note appearance=“minimal”}
Definición. . En un árbol de regresión, si una partición $s$ divide $D_t$ en $D_L$ y $D_R$, el criterio de error cuadrático puede escribirse como:
$$
RSS(s)=\sum_{i\in D_L}(y_i-\bar{y}_L)^2+\sum_{i\in D_R}(y_i-\bar{y}_R)^2.
$$ {#eq-rss-cart}
:::
Así, CART unifica problemas de clasificación y regresión bajo una misma lógica: dividir recursivamente el espacio de variables para formar regiones internamente homogéneas.
## Complejidad computacional
La complejidad de construir un árbol CART depende del número de observaciones $n$, el número de variables $m$, el tipo de variables y la profundidad final del árbol. Para variables numéricas, evaluar cortes requiere ordenar valores o mantener estructuras ordenadas. De manera simplificada, si se ordenan los valores de cada atributo, el costo inicial puede aproximarse por
$$
O(mn\log n).
$$
Después, en cada nodo, se evalúan cortes candidatos para seleccionar la mejor partición. En implementaciones eficientes, el costo total depende de cómo se reutilicen los ordenamientos y de las restricciones impuestas al crecimiento del árbol [@hastie2009elements; @scikit-learn-decision-trees].
Una forma práctica de interpretar la complejidad es la siguiente:
- $n$ controla cuántas observaciones deben repartirse y evaluarse;
- $m$ controla cuántos atributos se prueban en cada nodo;
- la profundidad controla cuántas veces se repite el proceso de partición;
- las variables categóricas con muchos niveles pueden ser costosas porque el número de particiones binarias crece como $2^{m-1}-1$ respecto al número de categorías del atributo.
Por esta razón, en aplicaciones reales se imponen restricciones como `max_depth`, `min_samples_split`, `min_samples_leaf` o poda por `ccp_alpha`.
## Ventajas y limitaciones
CART tiene varias ventajas:
- produce modelos interpretables;
- requiere pocas transformaciones de escala en variables numéricas;
- captura interacciones no lineales entre atributos;
- permite clasificación y regresión;
- puede combinarse con métodos de ensamble como Random Forests y Gradient Boosting [@breiman2001randomforests; @friedman2001greedy].
Sin embargo, también tiene limitaciones importantes:
- puede sobreajustarse si no se controla su profundidad;
- pequeñas variaciones en los datos pueden producir árboles distintos;
- las decisiones son locales y greedy;
- un árbol individual suele tener menor desempeño predictivo que ensambles de árboles;
- las variables categóricas con muchos niveles pueden inducir particiones complejas o inestables.
Estas limitaciones explican por qué CART suele utilizarse como modelo base dentro de métodos de ensamble. Aun así, su valor pedagógico e interpretativo sigue siendo fundamental.
## Conclusiones
CART es uno de los métodos clásicos más importantes para construir árboles de decisión. Su principio central consiste en dividir recursivamente los datos mediante particiones binarias que reduzcan la impureza de los nodos. En clasificación, el índice de Gini proporciona una medida sencilla y efectiva para evaluar la mezcla de clases; en regresión, se emplean criterios basados en la reducción del error cuadrático.
El enfoque CART combina interpretabilidad, flexibilidad y una formulación matemática clara. La selección de particiones mediante impureza ponderada, la comparación mediante reducción de impureza y la poda de costo-complejidad permiten construir árboles útiles sin perder de vista el riesgo de sobreajuste. Por ello, CART no solo es un modelo por derecho propio, sino también la base conceptual de técnicas modernas de ensamble ampliamente usadas en ciencia de datos.